
自然言語処理、プローブデータ処理、将来予想など、時系列データの処理が必要なシーンは結構あると思います。
時系列について知見を深めるため、時系列センサを取り扱うKaggleコンペの”CMI – Detect Behavior with Sensor Data”を見ていこうと思います。
CMI – Detect Behavior with Sensor Data | Kaggle
本記事ではコンペ概要と上位解法について解説していきます。
次回以降は上位解法におけるコア要素について実装を見ながら解説する予定です。
コンペ内容
概要
手首に取り付けるウェアラブルセンサーデータを用いて、BFRBs(Body-focused repetitive behaviors)という、いわゆる爪を噛む、髪の毛を抜くといった動作をしていないかを予測する。
被験者には以下のように動作してもらう。
- 自然な姿勢をとる
- 該当する動作を取る直前の位置まで手を動かす (例: 手を頭に持っていく)
- 該当動作を模擬した動きを反復
動作
■BFRBs該当動作:
髪を抜く、額をかく、眉毛を抜くといった計8動作
■BFRBs類似動作 ※該当動作の負例
飲み物を飲む、眼鏡の調整、顔の前で風を仰ぐといった計10動作
上記動作を行う際の姿勢として以下3つの姿勢がありうる。
- 普通の着座姿勢
- 前傾姿勢で膝に肘をかけて頬杖
- 横向きで手で頭を支えて寝てる状態

評価指標
前提:姿勢の判別は不要であり、動作を判別する。
■Binary F1
BFRBかそうでないかの2値分類のF1 score
■Macro F1
BFRBについては詳細な動作、BFRBでないものについてはBFRBではないと予測するマルチクラス分類のF1 score
上記2つのF1 scoreを平均したものが最終的な評価指標
データ
実際は時系列の表データだが以下のような構造。重要なデータのみ抜粋。
補足として、テストデータ内の半分のデータはIMUのデータしかなく、残り半分はIMU、測距センサ、温度センサのデータが揃っている。
sequence_id #ある被験者の一連の動作(自然な状態→準備動作→該当動作)のまとまり
- acc_[x/y/z] #IMUセンサのx,y,z方向加速度
- rot_[w/x/y/z] #IMUセンサの姿勢. クォータニオン形式.
- thm_[1-5] #5個ある温度センサのそれぞれの値
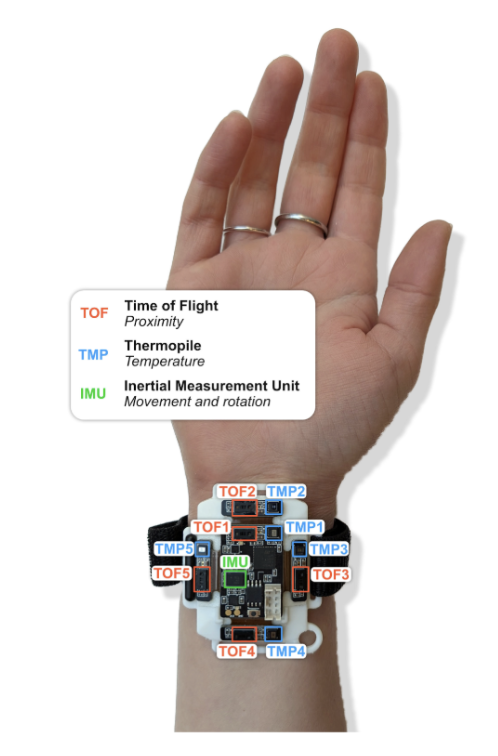
- tof_[1-5]_v[0-63] #5個ある測距センサのそれぞれの64ピクセル分の値. 下図参照.
- handedness #利き手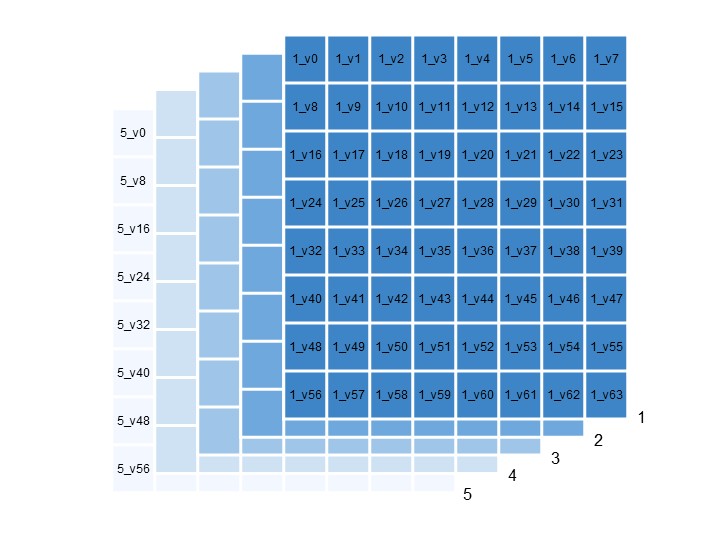
1~5が各センサであり、各センサに64ピクセル分のデータが存在
クォータニオン補足
詳細語ると長くなってしまうので必要なところだけ簡易的に説明しておきます。ここでは深く考えず、そうなんだくらいで流してください。
(そのうちIMUのクォータニオンに特化した記事を書こうかなと思います。)
クォータニオンとは座標系の回転表現の一つ。w, x, y, zで表されて、x, y, zが回転軸のベクトル、wが回転軸周りの回転の程度を示します。
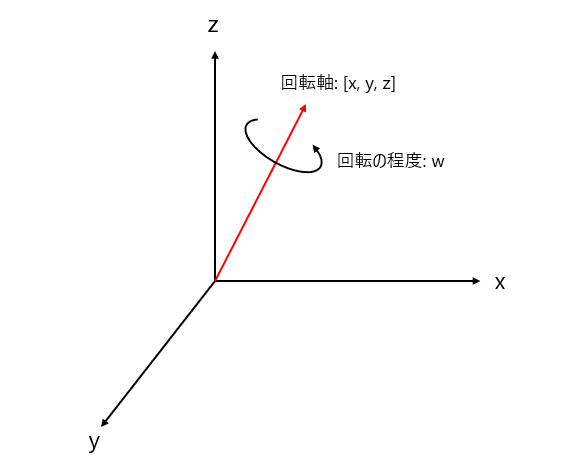
クォータニオンだと同じ回転なのに表現が二つ存在する場合があり、モデルの学習において正解なのにlossが大きく出るという問題があります。
以下に示すようにクォータニオンから回転行列を作れるのですが、回転行列では回転表現が1つに定まるため、AIモデルにとって都合がよいです。
回転行列の3列目は1列目と2列目が定まれば勝手に値が決まるものであり※、3列目は省略して、1列目と2列目を取得した6D表現をモデルの学習に使うと良いという話があります。(6D表現 元論文)
※一旦そういうものだと飲み込んでください。
後ほど紹介する解法で6D表現が使われてるので、クォータニオンのついでに説明しておきました。
クォータニオン回転行列
6D表現
上位解法概要
今回1位解法見ようとしたら、コードの方が中国語やロシア語が混ざり読むのが大変そうだったので2位の方のものを見ることにしました。(時系列へのAttention利用も見てみたかったのもあり)
以下にそれぞれの処理の要点を記載していきます。灰色の字で書いてるものは推測した内容です。
汎用性ある内容だけ抽出しており、タスクやkaggle特化してるものは省略してます。
AugmentationやPost-Processingは特化系だったの省略です。
Feature Engineering
- クォータニオンを6D表現に変換 (先ほどの内容)
- 左利きの被験者のデータについては各値を反転処理
※IMUのrotや反転処理については改善余地ありそうな気がするためIMUクォータニオンの記事で語るかも
Architecture
- SE-CNN Block + Attention model
→1D CNNで局所的な特徴をつかみ、Attentionで全体の関係性を見るため - 各センサ値に対してStemを作成. ここでのStemは1D CNN.
→acc, angular velocityなど、それぞれで特性は異なるため、個別で特徴量抽出 - シーケンス内の各ステップに対して”自然な姿勢”, “準備動作”, “該当動作反復”の3クラス分類して、各クラス(フェーズ)毎にAttentionを構築
→時系列Attentionだと反復動作といった短い周期で動くものよりも準備動作などの長周期のものを学習しやすい。
クラス分けしてそれぞれにAttentionすることで各フェーズの特徴を取得しやすくした。
時系列センサ処理の肝
※タスク特化の処理は除いて、上記の厳選した解法の内容に基づいて考察
- 時系列の局所部分の意味を抽出 → 1D CNN
- 抽出したそれぞれの局所的な意味の関係性を取得 → Attention
- データの特徴を確認するのは画像などの他のタスクでも当然大事だが、時系列は更に大事※
※同じ動作だが符号が異なり見た目が変わってるなど多々存在するため
まとめ
今回は時系列処理について知見を深めようと思い、時系列センサ系の題材を取り上げてみました。
解法から厳選した内容や肝として書いた内容はだいぶあっさりしてると思いますが、時系列の基礎部分になり他タスクにも応用できそうだと思い、あれこれ書かず本記事の内容に絞りました。
次回はモデルの実装を見ながら、モデルの役割・イメージを説明していく予定です。
最後までご覧いただきありがとうございました。

