
Kaggle BYU 2025の1位解法コードについて、実際に公開されているコードを確認しながら解説します。
公開解法:1st Place – 3D U-Net + Quantile Thresholding | Kaggle
参考リポジトリ:GitHub – brendanartley/BYU-competition: 1st place solution for the BYU Locating Bacterial Flagellar Motors Competition
今回は3D UnetのEncoder部分(Resnet200)について見ていきます。
【参照】関連記事リンク
- 解法解説:Cryo-ET 鞭毛モーターの3D検出 | Kaggle BYU 2025 1位解法解説
- コード解説:
- 3D Unet:
- Encoder部:本記事
- Decoder部:Coming soon
- 全体:Comming soon
- 学習/推論: Comming soon
- 3D Unet:
- 2位以下解法との差分:Comming soon
Encoder全体
ファイル※:src/models/layers/resnet3d.py
※記事最初に記載してある参考リポジトリのもの
from types import SimpleNamespace
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.layers import DropPath
from timm.models._manipulate import checkpoint
from .utils import load_weights
def conv3x3x3(ic, oc, stride=1):
return nn.Conv3d(
ic,
oc,
kernel_size=3,
stride=stride,
padding=1,
bias=False,
)
class BasicBlock(nn.Module):
def __init__(
self,
ic,
oc,
stride: int = 1,
downsample: bool = None,
expansion_factor: int = 1,
drop_path_rate: float = 0.0,
norm_layer: nn.Module = nn.BatchNorm3d,
act_layer: nn.Module = nn.ReLU,
):
super().__init__()
self.conv1 = conv3x3x3(ic, oc, stride)
self.bn1 = norm_layer(oc)
self.act = act_layer(inplace=True)
self.conv2 = conv3x3x3(oc, oc)
self.bn2 = norm_layer(oc)
self.drop_path= DropPath(drop_prob=drop_path_rate)
if downsample:
self.downsample = nn.Sequential(
nn.Conv3d(
ic * expansion_factor,
oc,
kernel_size=(1, 1, 1),
stride=(2,2,2),
bias=False
),
norm_layer(oc),
)
else:
self.downsample= nn.Identity()
def forward(self, x):
residual = x
x = self.conv1(x)
x = self.bn1(x)
x = self.act(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.drop_path(x)
residual = self.downsample(residual)
x += residual
x = self.act(x)
return x
class Bottleneck(nn.Module):
def __init__(
self,
ic,
oc,
stride: int = 1,
downsample: bool = None,
expansion_factor: int = 4,
drop_path_rate: float = 0.0,
norm_layer: nn.Module = nn.BatchNorm3d,
act_layer: nn.Module = nn.ReLU,
):
super().__init__()
self.conv1 = nn.Conv3d(ic * expansion_factor, oc, kernel_size=1, bias=False)
self.bn1 = norm_layer(oc)
self.conv2 = nn.Conv3d(oc, oc, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = norm_layer(oc)
self.conv3 = nn.Conv3d(oc, oc * 4, kernel_size=1, bias=False)
self.bn3 = norm_layer(oc * 4)
self.act = act_layer(inplace=True)
self.drop_path= DropPath(drop_prob=drop_path_rate)
if downsample is not None:
stride = (1,1,1) if expansion_factor == 1 else (2,2,2)
self.downsample = nn.Sequential(
nn.Conv3d(ic * expansion_factor, oc * 4, kernel_size=(1, 1, 1), stride=stride, bias=False),
norm_layer(oc * 4),
)
else:
self.downsample= nn.Identity()
def forward(self, x):
residual = x
x = self.conv1(x)
x = self.bn1(x)
x = self.act(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.act(x)
x = self.conv3(x)
x = self.bn3(x)
x = self.drop_path(x)
residual = self.downsample(residual)
x += residual
x = self.act(x)
return x
class ResnetEncoder3d(nn.Module):
def __init__(
self,
cfg: SimpleNamespace,
inference_mode: bool = False,
drop_path_rate: float = 0.2,
in_stride: tuple[int]= (2,2,2),
in_dilation: tuple[int]= (1,1,1),
use_checkpoint: bool = False,
):
super().__init__()
self.cfg= cfg
self.use_checkpoint= use_checkpoint
# Backbone configs
bb= self.cfg.backbone
backbone_cfg= {
"r3d18": ([2, 2, 2, 2], BasicBlock),
"r3d200": ([3, 24, 36, 3], Bottleneck),
}
if bb in backbone_cfg:
layers, block = backbone_cfg[bb]
wpath = "./data/model_zoo/{}_KM_200ep.pt".format(bb)
else:
raise ValueError(f"ResnetEncoder3d backbone: {bb} not implemented.")
# Drop_path_rates (linearly scaled)
num_blocks = sum(layers)
flat_drop_path_rates = [drop_path_rate * (i / (num_blocks - 1)) for i in range(num_blocks)]
drop_path_rates = []
start = 0
for b in layers:
end = start + b
drop_path_rates.append(flat_drop_path_rates[start:end])
start = end
# Stem
in_padding= tuple(_*3 for _ in in_dilation)
self.conv1 = nn.Conv3d(
in_channels= 3,
out_channels= 64,
kernel_size= (7, 7, 7),
stride= in_stride,
dilation= in_dilation,
padding= in_padding,
bias= False,
)
self.bn1 = nn.BatchNorm3d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool3d(kernel_size=(3, 3, 3), stride=2, padding=1)
# Blocks
self.layer1 = self._make_layer(
ic=64, oc=64, block=block, n_blocks=layers[0], stride=1, downsample=False,
drop_path_rates= drop_path_rates[0],
)
self.layer2 = self._make_layer(
ic=64, oc=128, block=block, n_blocks=layers[1], stride=2, downsample=True,
drop_path_rates=drop_path_rates[1],
)
self.layer3 = self._make_layer(
ic=128, oc=256, block=block, n_blocks=layers[2], stride=2, downsample=True,
drop_path_rates=drop_path_rates[2],
)
self.layer4 = self._make_layer(
ic=256, oc=512, block=block, n_blocks=layers[3], stride=2, downsample=True,
drop_path_rates=drop_path_rates[3],
)
# Load pretrained weights
if not inference_mode:
load_weights(self, wpath)
# In channels
self._update_input_channels()
# Encoder channels
with torch.no_grad():
out = self.forward_features(torch.randn((1, self.cfg.in_chans, 96, 96, 96)))
self.channels = [o.shape[1] for o in out]
del out
def _make_layer(
self, ic, oc, block, n_blocks, stride=1, downsample=False,
drop_path_rates=[],
):
layers = []
if downsample:
layers.append(
block(
ic=ic, oc=oc, stride=stride, downsample=downsample,
drop_path_rate=drop_path_rates[0],
),
)
else:
layers.append(
block(
ic=ic, oc=oc, stride=stride, downsample=downsample, expansion_factor=1,
drop_path_rate=drop_path_rates[0],
),
)
for i in range(1, n_blocks):
layers.append(block(oc, oc, drop_path_rate=drop_path_rates[i]))
return nn.Sequential(*layers)
def _update_input_channels(self, ):
with torch.no_grad():
# Get stem
b= self.conv1
# Update channels
ic= self.cfg.in_chans
b.in_channels = ic
w = b.weight.sum(dim=1, keepdim=True) / ic
b.weight = nn.Parameter(w.repeat([1, ic] + [1] * (w.ndim - 2)))
return
def _checkpoint_if_enabled(self, module, x):
return checkpoint(module, x) if self.use_checkpoint else module(x)
def forward_features(self, x):
res= []
# Stem
x = self._checkpoint_if_enabled(self.conv1, x)
x = self.bn1(x)
x = self.relu(x)
res.append(x)
x = self.maxpool(x)
# Layers
layers = [self.layer1, self.layer2, self.layer3, self.layer4]
for layer in layers:
x = self._checkpoint_if_enabled(layer, x)
res.append(x)
return res
def forward(self, x):
# Stem
x = self._checkpoint_if_enabled(self.conv1, x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
# Layers
layers = [self.layer1, self.layer2, self.layer3, self.layer4]
for layer in layers:
x = self._checkpoint_if_enabled(layer, x)
return x
if __name__ == "__main__":
from .utils import count_parameters
cfg= SimpleNamespace()
cfg.backbone= "r3d18"
# cfg.backbone= "r3d200"
cfg.in_chans= 1
cfg.encoder_cfg= SimpleNamespace()
cfg.encoder_cfg.use_checkpoint= True
cfg.roi_size= (32, 128, 128)
m = ResnetEncoder3d(
cfg= cfg,
inference_mode= False,
**vars(cfg.encoder_cfg),
).eval()
# Param count
n_params= count_parameters(m)
print(f"Model: {type(m).__name__}")
print("n_param: {:_}".format(n_params))
# Normal
x = torch.ones(8, cfg.in_chans, *cfg.roi_size)
with torch.no_grad():
z = m.forward_features(x)
print(x.shape)
print([_.shape for _ in z])
# # Channels Last check
# x = torch.ones(8, cfg.in_chans, 32, 128, 128)
# print("stride_before:", x.stride())
# x= x.to(memory_format=torch.channels_last_3d)
# print("stride_after:", x.stride()) # check the stride change
# with torch.no_grad():
# z = m.forward_features(x)
# print([_.shape for _ in z])Encoderには事前学習済みのResnet200(200層の深いResnet)が使われてます。
Resnetの詳細は割愛させていただきますが、畳み込み前のデータをスキップさせて畳み込み後の結果と接続します。(残差接続, Residual Connection)
“データをスキップ、データを畳み込み、スキップしたデータと畳み込んだ結果を接続”をひとまとめにしたものをブロックと呼び、ブロックを積み重ねてResnetを構築します。
実際のコードでは、”畳み込み層の定義”、”定義した畳み込み層等を用いてブロックを定義”、”定義したブロックを用いてResnet全体の構築”というように適度に抽象化されているのでそれぞれ解説していきます。
BasicBlockクラスについては最終的に使われてないため解説はスキップします。Bottleneckクラスの解説内で今回の解法においてBasicBlockクラスが使われていない理由について軽く紹介します。
conv3x3x3
def conv3x3x3(ic, oc, stride=1):
return nn.Conv3d(
ic,
oc,
kernel_size=3,
stride=stride,
padding=1,
bias=False,
)ic: input channel
oc: output channel
こちらは3次元畳み込み層の定義です。
biasについて、Resnetのような深いモデル特有の設定になっているため説明しておきます。
まず、bias=Falseでは線形変換”“のバイアス項を除いてます。
Resnetのように深い層のモデルでは学習の安定化や汎化性能を上げるため、畳み込み層の後にバッチ正則化を入れることが多いです。
バッチ正則化において、まず出力yの正規化が行われるので畳み込み層でのバイアス成分はほぼ失われます。
加えて、バッチ正則化において学習するパラメータにバイアス項と同じ役割のパラメータもあるため、畳み込み時のバイアスは冗長であり、バッチ正則化を入れる場合はbias=Falseとします。
【補足】3次元畳み込み
3次元畳み込みについては基本の話であり冗長かもしれませんが、後ほど頭が混乱してくるので念のためイメージを図示しておきます。不要であればスキップしてください。
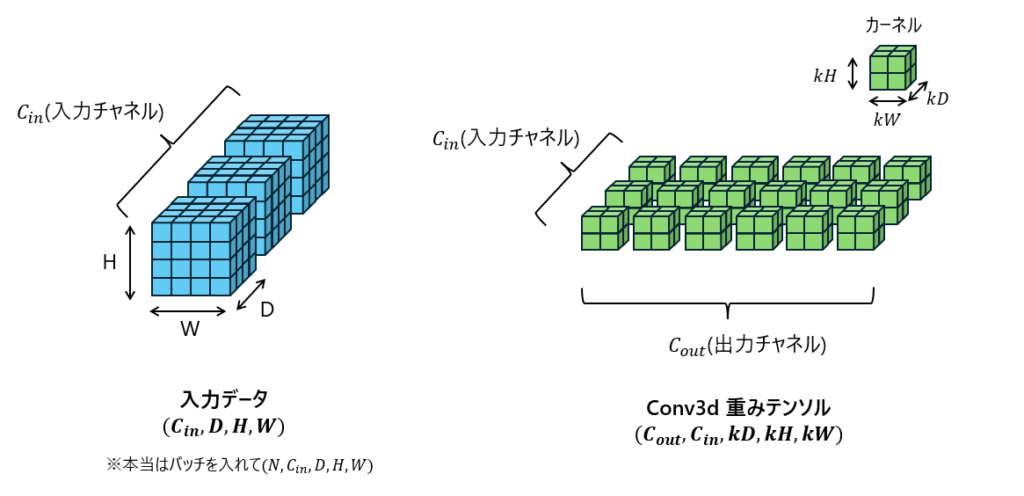
3次元畳み込みで基本となる入力データと畳み込み用の重みテンソルの構造については図1を参照。
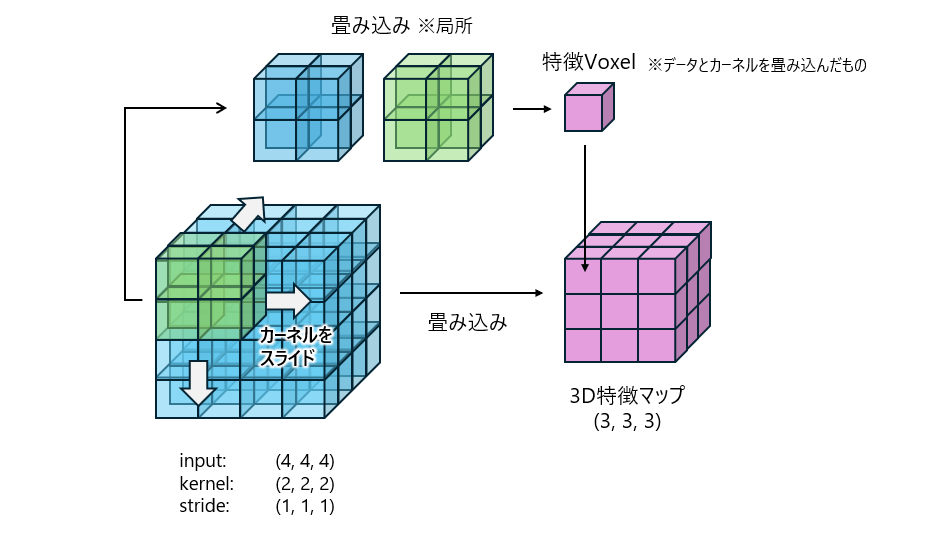
3次元データの1つのチャネルと1つのカーネルの畳み込みのイメージが図2です。
1つの格子(voxel)に1つの値が入っていると思って見てください。
青いブロックの方は入力データ、緑のブロックはカーネルとなっているため、特徴Voxel(紫)の値は積和を取りとなります。
カーネルをD/H/Wそれぞれの方向にスライドさせて3D特徴マップを作成していきます。
入力データの全チャネルと全カーネルで畳み込みが行われ、出力されていく様子を示したのが図3です。
※出力データ(オレンジ)のチャネルの整列方向が入力データ(青)のチャネルの整列方向と向きが変わってしまってるのはよろしくないですが、イメージ優先にしてあえてこのようにしてます。
重みテンソル(緑)において、毎に入力データのチャネルと同じ数だけのカーネルがあります。図では一つに対しての3カーネル。
のカーネルは入力のチャネルと畳み込み、カーネルは入力のチャネルと…
のカーネルは入力のチャネルと畳み込み、カーネルは入力のチャネルと…
といったように対応するデータとカーネルを畳み込んでいき、各チャネルの特徴マップ(紫)を作成していきます。
最後に入力チャネル方向に対してvoxel-wiseで足し合わせて完了となります。
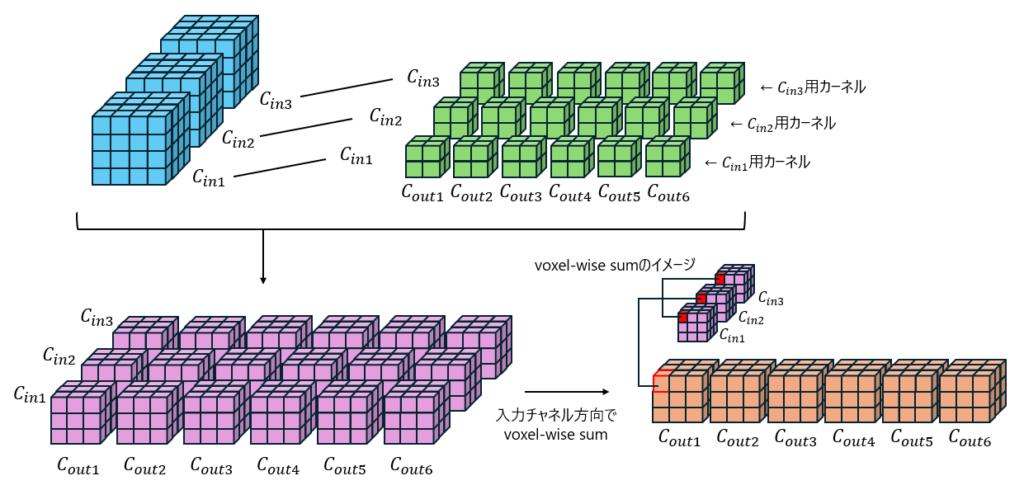
私だけかもしれませんが、2次元の場合だと”カーネルの数に応じて出力チャネルの数が変わる”というのはすんなり頭に入ったのですが、3次元になった途端に拒否反応起きたので備忘録も兼ねて補足しておきました。
Bottleneck
こちらはブロック(Bottleneck)の定義となります。
はじめにブロックの概念について説明した後に実装内容について確認していきます。
BasicBlock vs Bottleneck
ブロックの実装内容の説明に入る前にブロックの概念について説明します。
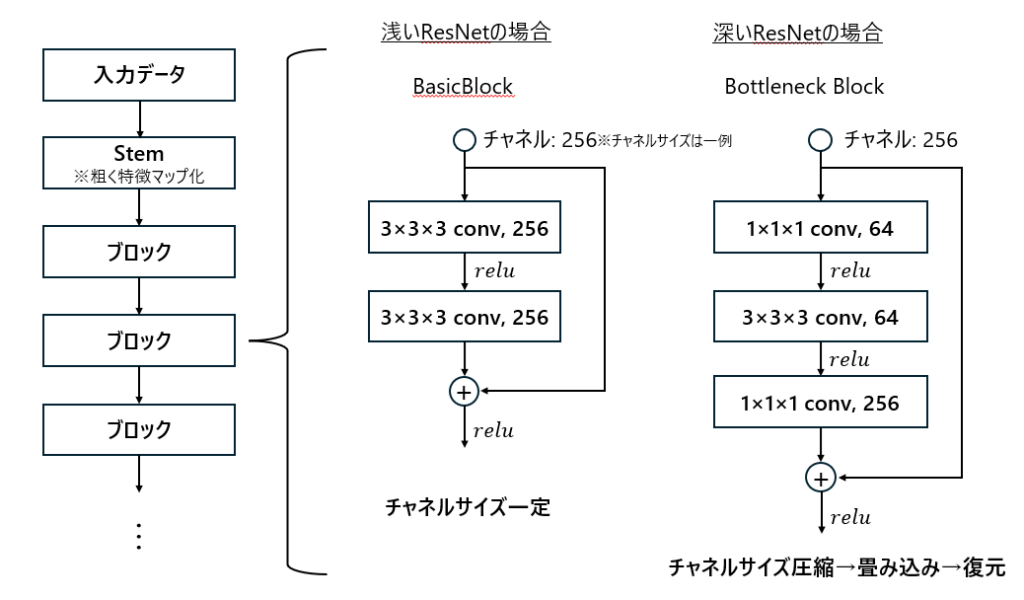
冒頭でResnetはブロックを積み上げて構成するという話をしたかと思いますが、ブロックにも種類があり、主にBasicBlockとBottleneckの2つです。
図4をご覧ください。
各boxの末尾に書いてある数字は出力チャネルのサイズを示しており、今回記載している64, 256は一例です。チャネルの絶対値は重要ではなく、相対値(小さくなったか, 大きくなったか)が重要なのでそちらに注目してください。
BasicBlockではチャネルサイズが終始変わらず、Bottleneckでは一度サイズが小さくなり、その後サイズが戻っていることがわかると思います。
1x1x1の畳み込みはのサイズを変えずにチャネルサイズだけを変えるものとなります。
層が深い場合だと計算量が多くなるため、極力計算量を減らしたい、ただし表現力は落としたくない。そのため、一番計算が重い3次元の畳み込み(3x3x3)の前にチャネルサイズを落として、畳み込みが終わったら再度チャネルサイズを復元するということを行います。
この一連の処理をまとめたブロックがBottleneckです。
今回は200層と層が深いのでBasicBlockではなくBottleneckが採用されています。
Bottleneck実装
class Bottleneck(nn.Module):
def __init__(
self,
ic,
oc,
stride: int = 1,
downsample: bool = None,
expansion_factor: int = 4,
drop_path_rate: float = 0.0,
norm_layer: nn.Module = nn.BatchNorm3d,
act_layer: nn.Module = nn.ReLU,
):
super().__init__()
self.conv1 = nn.Conv3d(ic * expansion_factor, oc, kernel_size=1, bias=False)
self.bn1 = norm_layer(oc)
self.conv2 = nn.Conv3d(oc, oc, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = norm_layer(oc)
self.conv3 = nn.Conv3d(oc, oc * 4, kernel_size=1, bias=False)
self.bn3 = norm_layer(oc * 4)
self.act = act_layer(inplace=True)
self.drop_path= DropPath(drop_prob=drop_path_rate)
if downsample is not None:
stride = (1,1,1) if expansion_factor == 1 else (2,2,2)
self.downsample = nn.Sequential(
nn.Conv3d(ic * expansion_factor, oc * 4, kernel_size=(1, 1, 1), stride=stride, bias=False),
norm_layer(oc * 4),
)
else:
self.downsample= nn.Identity()
def forward(self, x):
residual = x
x = self.conv1(x)
x = self.bn1(x)
x = self.act(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.act(x)
x = self.conv3(x)
x = self.bn3(x)
x = self.drop_path(x)
residual = self.downsample(residual)
x += residual
x = self.act(x)
return xコードについて説明すると言いましたが先ほどのBottleneckの説明でほとんど完結してます。
Bottleneckコードでは図4で記載したBottleneckのブロックを定義しているだけです。
このように実装されてるんだくらいの感じで見てもらえればOKです。
downsampleのところはスキップ(residual)させるデータを畳み込み後のデータの次元を一致させるためにしています。
他に先ほどの図4に含まれておらず注意が必要なものとしては以下になります。
- 畳み込み層の後に必ずバッチ正則化(BN: Batch Normalization)が挟まれている
- スキップしたデータと結合する直前にDropPathを入れられている。
1についてはconv3x3x3のところで話した通り学習の安定化、汎化性能向上のために入ってます。
2は、畳み込み1(conv1)→BN1→活性化(act)→畳み込み2(conv2)→ … →BN3というメインの処理を確率的にDropoutさせるものであり、これによって勾配を伝播させやすくして、加えて特定ブロックへの依存を防ぐ正則化となってます。
解法だとVRAM節約するために使用しているという記述もありました。
ResnetEncoder3d
class ResnetEncoder3d(nn.Module):
def __init__(
self,
cfg: SimpleNamespace,
inference_mode: bool = False,
drop_path_rate: float = 0.2,
in_stride: tuple[int]= (2,2,2),
in_dilation: tuple[int]= (1,1,1),
use_checkpoint: bool = False,
):
super().__init__()
self.cfg= cfg
self.use_checkpoint= use_checkpoint
# Backbone configs
bb= self.cfg.backbone
backbone_cfg= {
"r3d18": ([2, 2, 2, 2], BasicBlock),
"r3d200": ([3, 24, 36, 3], Bottleneck),
}
if bb in backbone_cfg:
layers, block = backbone_cfg[bb]
wpath = "./data/model_zoo/{}_KM_200ep.pt".format(bb)
else:
raise ValueError(f"ResnetEncoder3d backbone: {bb} not implemented.")
# Drop_path_rates (linearly scaled)
num_blocks = sum(layers)
flat_drop_path_rates = [drop_path_rate * (i / (num_blocks - 1)) for i in range(num_blocks)]
drop_path_rates = []
start = 0
for b in layers:
end = start + b
drop_path_rates.append(flat_drop_path_rates[start:end])
start = end
# Stem
in_padding= tuple(_*3 for _ in in_dilation)
self.conv1 = nn.Conv3d(
in_channels= 3,
out_channels= 64,
kernel_size= (7, 7, 7),
stride= in_stride,
dilation= in_dilation,
padding= in_padding,
bias= False,
)
self.bn1 = nn.BatchNorm3d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool3d(kernel_size=(3, 3, 3), stride=2, padding=1)
# Blocks
self.layer1 = self._make_layer(
ic=64, oc=64, block=block, n_blocks=layers[0], stride=1, downsample=False,
drop_path_rates= drop_path_rates[0],
)
self.layer2 = self._make_layer(
ic=64, oc=128, block=block, n_blocks=layers[1], stride=2, downsample=True,
drop_path_rates=drop_path_rates[1],
)
self.layer3 = self._make_layer(
ic=128, oc=256, block=block, n_blocks=layers[2], stride=2, downsample=True,
drop_path_rates=drop_path_rates[2],
)
self.layer4 = self._make_layer(
ic=256, oc=512, block=block, n_blocks=layers[3], stride=2, downsample=True,
drop_path_rates=drop_path_rates[3],
)
# Load pretrained weights
if not inference_mode:
load_weights(self, wpath)
# In channels
self._update_input_channels()
# Encoder channels
with torch.no_grad():
out = self.forward_features(torch.randn((1, self.cfg.in_chans, 96, 96, 96)))
self.channels = [o.shape[1] for o in out]
del out
def _make_layer(
self, ic, oc, block, n_blocks, stride=1, downsample=False,
drop_path_rates=[],
):
layers = []
if downsample:
layers.append(
block(
ic=ic, oc=oc, stride=stride, downsample=downsample,
drop_path_rate=drop_path_rates[0],
),
)
else:
layers.append(
block(
ic=ic, oc=oc, stride=stride, downsample=downsample, expansion_factor=1,
drop_path_rate=drop_path_rates[0],
),
)
for i in range(1, n_blocks):
layers.append(block(oc, oc, drop_path_rate=drop_path_rates[i]))
return nn.Sequential(*layers)
def _update_input_channels(self, ):
with torch.no_grad():
# Get stem
b= self.conv1
# Update channels
ic= self.cfg.in_chans
b.in_channels = ic
w = b.weight.sum(dim=1, keepdim=True) / ic
b.weight = nn.Parameter(w.repeat([1, ic] + [1] * (w.ndim - 2)))
return
def _checkpoint_if_enabled(self, module, x):
return checkpoint(module, x) if self.use_checkpoint else module(x)
def forward_features(self, x):
res= []
# Stem
x = self._checkpoint_if_enabled(self.conv1, x)
x = self.bn1(x)
x = self.relu(x)
res.append(x)
x = self.maxpool(x)
# Layers
layers = [self.layer1, self.layer2, self.layer3, self.layer4]
for layer in layers:
x = self._checkpoint_if_enabled(layer, x)
res.append(x)
return res
def forward(self, x):
# Stem
x = self._checkpoint_if_enabled(self.conv1, x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
# Layers
layers = [self.layer1, self.layer2, self.layer3, self.layer4]
for layer in layers:
x = self._checkpoint_if_enabled(layer, x)
return xようやくResnetを構築するところまで辿り着きました…
ここでやってること自体はわかれば単純です。図5をご覧ください。
ResnetEncoder3dでやられていることは主に以下の内容となります。
- Bottleneckを積み上げて各layerを構築※
※layerだと畳み込み層などの最小単位と混同するので命名はよろしくないですが、実際のコードに合わせてlayerと記述します。 - 各layerを積み上げてResnet全体を構築
- 3D-UnetのDecoderに渡す情報として、各layerの出力チャネルサイズと出力結果(torch.Tensor)を取得してリスト化
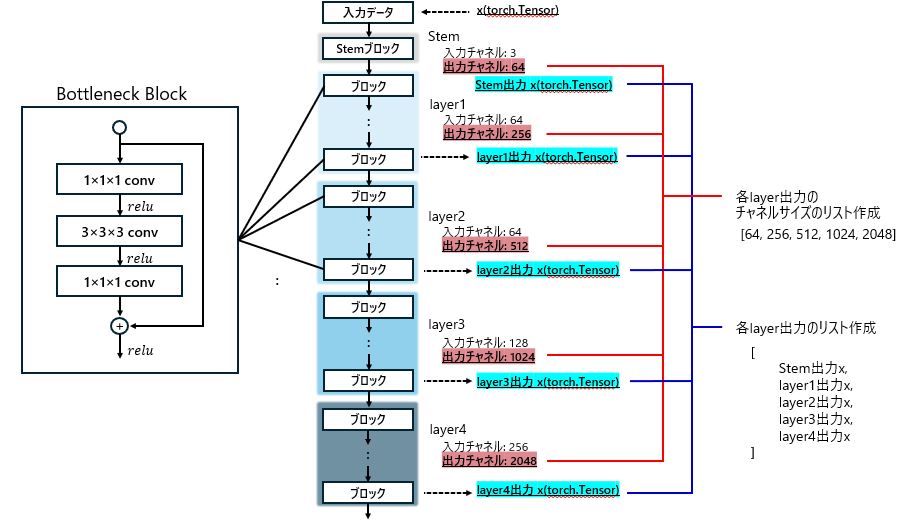
実装内容について順を追って説明していきます。
_make_layerメソッドを定義して、渡したblockを指定した数(n_blocks)だけ積み上げられるようにします。その際に一緒に入力チャネルと出力チャネルサイズも指定します。
def _make_layer(
self, ic, oc, block, n_blocks, stride=1, downsample=False,
drop_path_rates=[],
):
layers = []
if downsample:
layers.append(
block(
ic=ic, oc=oc, stride=stride, downsample=downsample,
drop_path_rate=drop_path_rates[0],
),
)
else:
layers.append(
block(
ic=ic, oc=oc, stride=stride, downsample=downsample, expansion_factor=1,
drop_path_rate=drop_path_rates[0],
),
)
for i in range(1, n_blocks):
layers.append(block(oc, oc, drop_path_rate=drop_path_rates[i]))
return nn.Sequential(*layers)_make_layerメソッド利用してlayerを積み重ねていくんですが、その際に積層するブロックと各layerでどのくらいブロックを積むかの情報は以下にあります。
今回は最終的にr3d200が使われてるのでlayer1が3ブロック, layer2が24ブロック, layer3が36ブロック, layer4が3ブロック、使用するブロックはBottleneckとなってます。
# def __init__()内
backbone_cfg= {
"r3d18": ([2, 2, 2, 2], BasicBlock),
"r3d200": ([3, 24, 36, 3], Bottleneck),
}以下のコードの場所で_make_layerを使用して各layerを作成しています。
# def __init__内
# Stem
in_padding= tuple(_*3 for _ in in_dilation)
self.conv1 = nn.Conv3d(
in_channels= 3,
out_channels= 64,
kernel_size= (7, 7, 7),
stride= in_stride,
dilation= in_dilation,
padding= in_padding,
bias= False,
)
self.bn1 = nn.BatchNorm3d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool3d(kernel_size=(3, 3, 3), stride=2, padding=1)
# Blocks
self.layer1 = self._make_layer(
ic=64, oc=64, block=block, n_blocks=layers[0], stride=1, downsample=False,
drop_path_rates= drop_path_rates[0],
)
self.layer2 = self._make_layer(
ic=64, oc=128, block=block, n_blocks=layers[1], stride=2, downsample=True,
drop_path_rates=drop_path_rates[1],
)
self.layer3 = self._make_layer(
ic=128, oc=256, block=block, n_blocks=layers[2], stride=2, downsample=True,
drop_path_rates=drop_path_rates[2],
)
self.layer4 = self._make_layer(
ic=256, oc=512, block=block, n_blocks=layers[3], stride=2, downsample=True,
drop_path_rates=drop_path_rates[3],
)各layerの出力(torch.Tensor)を取得してリスト化するのはforward_featuresメソッドになります。
ちなみにこれまでも度々見え隠れしているStemというのが登場してますが、後ほど補足で説明します。
また、途中で呼ばれているcheckpoint_if_enabledはgradient checkpointingというVRAM節約術をしているのでこちらも後ほど補足で軽く説明します。
def forward_features(self, x):
res= []
# Stem
x = self._checkpoint_if_enabled(self.conv1, x)
x = self.bn1(x)
x = self.relu(x)
res.append(x)
x = self.maxpool(x)
# Layers
layers = [self.layer1, self.layer2, self.layer3, self.layer4]
for layer in layers:
x = self._checkpoint_if_enabled(layer, x)
res.append(x)
return resコンストラクタ(__init__)の最後に以下のコードがありますが、ここでforward_featuresメソッドを呼び各layerの出力チャネル取得&リスト化しています。
forward_featuresにダミーデータを渡してout(各layerの出力のリスト)を取得。その後、チャネル部分だけを取得してリスト化されてますね。
Resnetを通るtorch.Tensorのデータはとなっているためo.shape[1]がチャネルCのところを指してます。
# def __init__内
# Encoder channels
with torch.no_grad():
out = self.forward_features(torch.randn((1, self.cfg.in_chans, 96, 96, 96)))
self.channels = [o.shape[1] for o in out]
del out
最後の出力のリストとチャネルのリストについてはEncoderモデル定義にはあまり関係ないですが、Decoderと組み合わせてUNetを完成させる際に必要となります。
補足
Stemについて
Bottleneckなどのブロックは特徴マップを処理する前提となっているため、いきなり生データをブロックに入れないように下処理的に特徴マップを作る前処理がStemになります。
_update_input_channelsメソッドについて
本文でスルーしてましたが、ResnetEncoder3dの中に_update_input_channelsメソッドがあり、Stemと関係があるのでこちらで補足することにしました。
※補足と言いながら内容を書いたら少々長くなったので折りたたむことにしました。
ここまででお腹いっぱいだったら一旦スキップしてください。
こちらのメソッドは、事前学習済みモデルのStem部分の入力チャネルサイズを変更するためのものになります。
事前学習したモデルを使用しようとしたときに、そのタスクにおける入力データのチャネルサイズが事前学習時と異なった場合は入力できないのでチャネルサイズの変更が必要であるため、この処理があります。
また、その際に折角事前学習されていたStemの値も使いたいため工夫がされてますが、コードを見ながら確認していきます。
以下が_update_input_channelsのコードです。概要も記載しておきます。
- b = self.conv1でStemの畳み込み層を取得
- “w = b.weight.sum(dim=1, keepdim=True) / ic”のところでは事前学習済みの重みの各voxelをチャネル方向で平均して、チャネルサイズを1につぶしこみ
- “b.weight = nn.Parameter(w.repeat([1, ic] + [1] * (w.nvim – 2)))”のところは、
- w.ndimはのためw.ndim=5
- [1, ic] + [1] * (w.ndim – 2) → [1, ic, 1, 1, 1]
- w.repeat([1, ic, 1, 1, 1])となり、のカーネルをチャネル方向にic個だけ複製
※カーネルの各voxelには2で平均した値が入ってる。 - nn.Parameterとすることで学習させるパラメータであることを認識
Stemの重みを0などにはせず平均にすることで事前学習の情報は残すということをしてますね。
def _update_input_channels(self, ):
with torch.no_grad():
# Get stem
b= self.conv1
# Update channels
ic= self.cfg.in_chans
b.in_channels = ic
w = b.weight.sum(dim=1, keepdim=True) / ic
b.weight = nn.Parameter(w.repeat([1, ic] + [1] * (w.ndim - 2)))
returngradient checkpointingについて
途中で記載していたようにVRAM節約術です。
誤差逆伝播するために通常はforward時に全ての中間層の計算結果を保存して、backward時にそれらの値を使用して勾配計算されます。
深い層だと全ての中間値を保持するとサイズが巨大になりVRAMが足りなくなります。
gradient checkpointingを適用することによってforward時は中間値を保持せず、backward時に勾配算出する層までを再度forwardして、必要な中間値だけを残して勾配計算します。
何度もforwardを計算することになるので学習時間は長くなってしまいますが、VRAMに載るようになるというテクニックです。
まとめ
UNetのEncoder部分だけでしたが結構な分量になってしまいました。
この後はDecoder、EncoderとDecoderを組み合わせてUNet全体の話、学習/推論といった内容が残ってますが、ここが一番重い気がします。
今回Encoderのところで次元のイメージを念入りに話しましたが、次元をつかめれば残りの話はほとんど実装はこうするんだくらいの話になるため脳の負荷は下がると思います。
次回はDecorder部分の話をします。
