
時系列センサ処理のモデルの知見を深めるために2025年のKaggleコンペ”CMI -Detect Behavior with Sensor Data”の上位解法で使用されているモデルについて見ていきます。
他にも色々処理する方法はあると思いますが、今回のは内容はあくまでも一つの代表例として見ていただければと思います。
こちらのコンペ、データがどういうものかについては前回記事をご覧ください。
【参考】各種リンク
コンペ:CMI – Detect Behavior with Sensor Data | Kaggle
参考にした解法:2nd Place Solution | Kaggle
解法のGithub:2nd Place Solution | Kaggle
概要
姿勢や加速度といった時系列のセンサデータがあり、どういう行動をしているかを時系列センサ情報から判定するという多クラス分類のタスクとなります。
時系列センサから特徴量を抽出する処理の主な流れとしては以下になります。
- 加速度時系列データ(acc_[x/y/z]), 角加速度時系列データ(rot_[x/y/z]), …といった感じに、センサ値の種別ごとに分離
- 各時系列データそれぞれに対して個別に以下の処理を実施
- 1D CNN (時系列の局所特徴取得)
- SE: Squeeze-and-Excitation (畳み込み後のチャネル間の関係性取得)
- Attention (時系列全体の関係性)
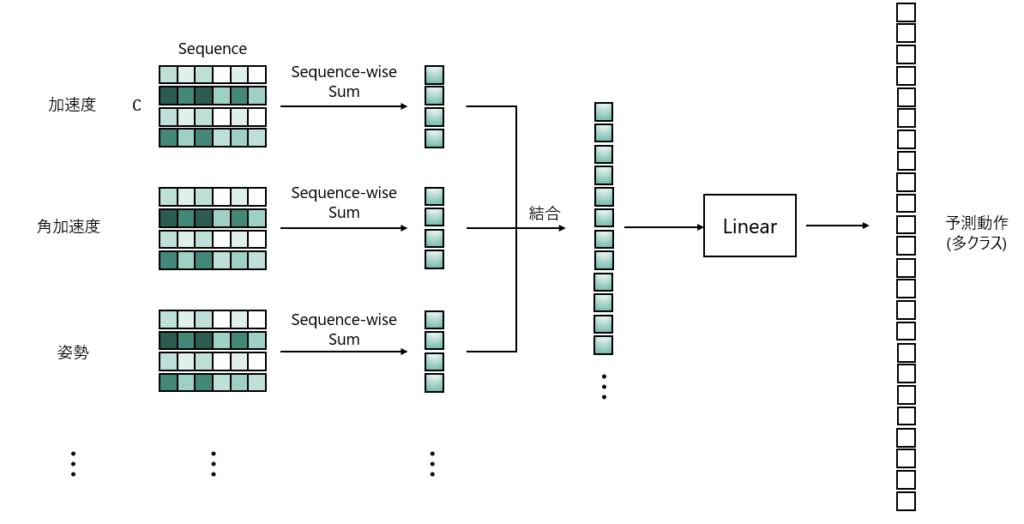
- 各処理結果を連結して一つの特徴量ベクトルにまとめてLinearに入力
上記をまとめた内容が以下の図になります。
※実際のモデルはBatch NormalizationやReLU、torch.Tensorの転置などの細かい処理、CNNの積層具合といった構造に関する処理もありますが、情報量が増えすぎて要点がわからなくなるため、あえて簡略化して要点だけを記載したものにしてます。
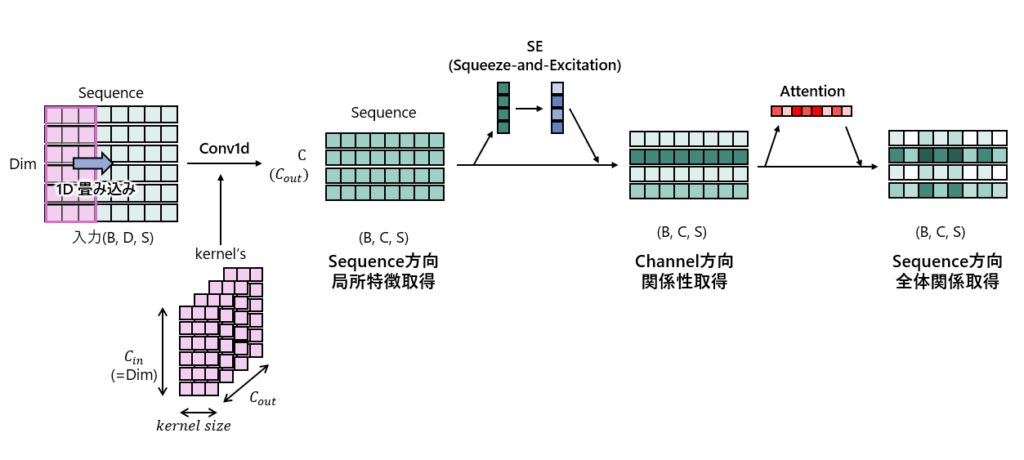
入力のDimはセンサパラメータ.
例)dim=1→acc_x, dim→2:acc_y, dim→3:acc_z
各処理についてそれぞれ詳細に見ていきます。
1D CNN
1D CNNはそのままの1D CNNです。
以下の図に示すように時系列方向への畳み込みを行い、時系列の局所的な特徴を抽出します。
今回の処理の場合はDim(acc_x, acc_yといった各センサパラメータ)が以下の図のに該当します。
畳み込み後はチャネル方向に圧縮されますが、これにより各センサパラメータが一つのチャネルに集約されるという意識をもっておくと良いです。
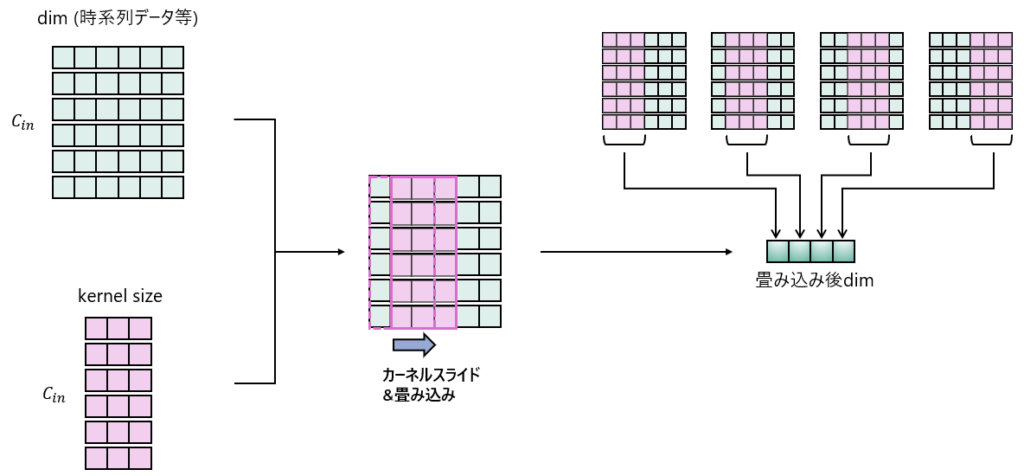
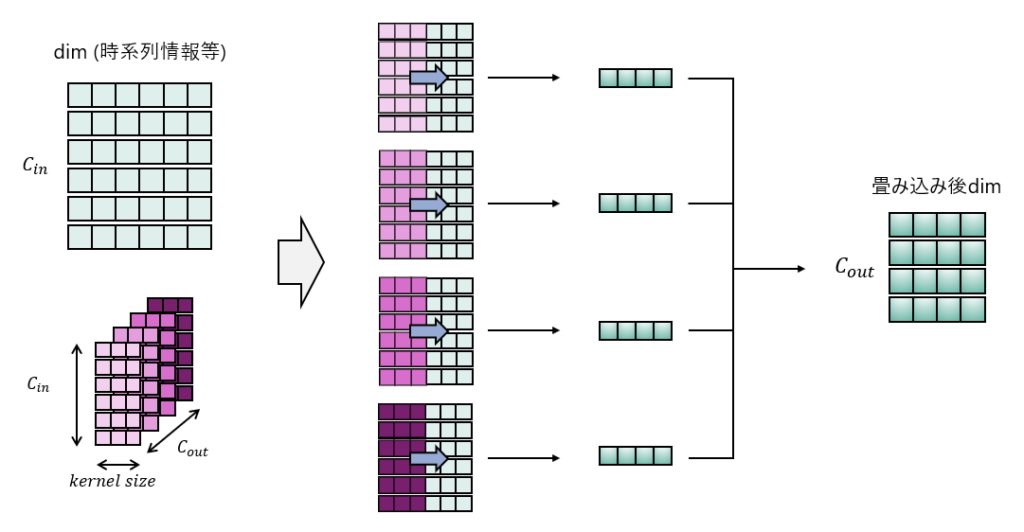
図3は単発でのカーネルでの畳み込みのイメージを示してますが、実際には図4のように複数カーネルを用いて複数チャネルが出力されます。
畳み込み後のチャネルは、各センサパラメータを考慮した時系列特徴となっており、チャネル分だけ異なる観点で時系列特徴があると見ておくと良いです。
SE(Squeeze-and-Excitation)
元論文はこちらになります。
CNNで複数チャネルが出力されるとき、CNNのみでもチャネル方向の関係性はある程度は考慮されたものになってますが、明示的にチャネル方向の関係を学習させるものになります。
以下でGlobal Average Poolingというのが行われてますが、これは時系列方向を平均してサイズ1になるように圧縮する処理です。
チャネルだけにして、全結合を通してチャネルの関係性を学習して、元データに関係性(重み)を掛け合わせるというものです。
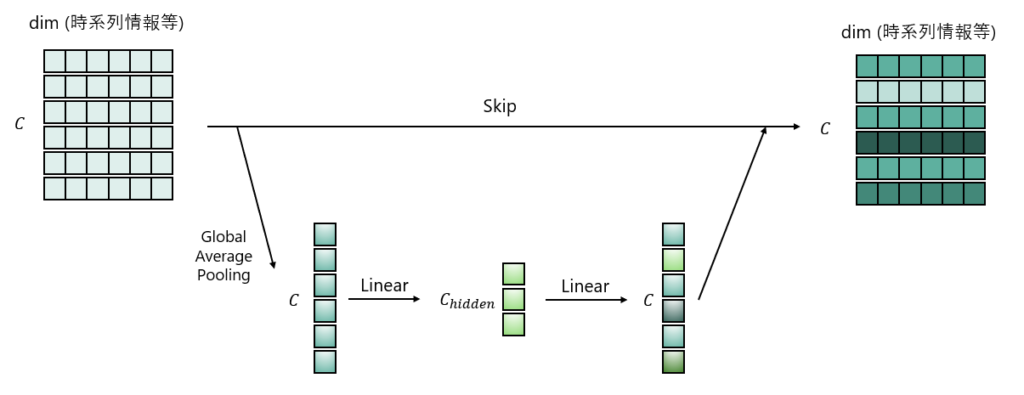
こちらの処理によって、より明確にチャネル方向の関係性を取得することになります。
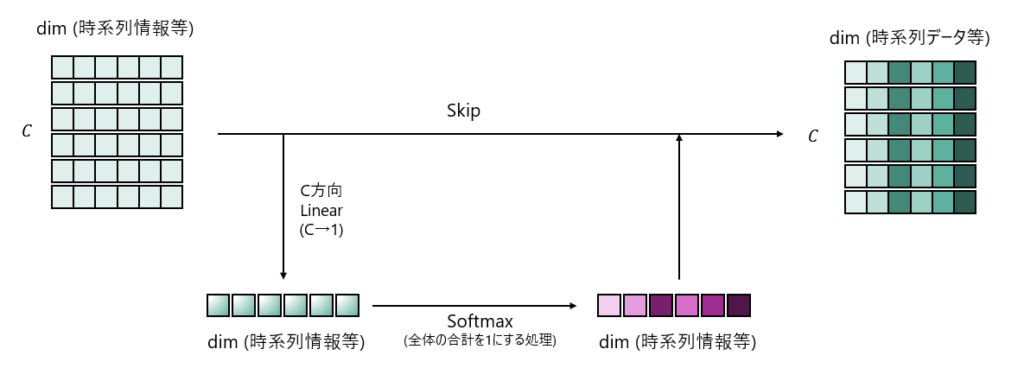
Attention
Attention元論文のAttention Is All You NeedのAttentionの概念は使われてますが、いわゆるSelf-AttentionやCross Attentionではないのでご注意ください。
やっていることはシンプルであり、チャネル方向を全結合でサイズ1に落とし込み時系列のみの形状として、Softmaxで値を調整して元データにかけているというものになります。
全結合層が時系列方向の関係性を学習していくものと推測されます。
1D CNN × Attention
先ほどのAttentionの説明のところで、各チャネルごとにAttentionを用意しなくてよいのか?と疑問に思った方がいたかもしれません。私は疑問に思って沼りました(笑)
結果としてはこれで大丈夫そうです。
まず、1D CNNが行われており、1D CNNの後にこちらのAttentionが行われています。
チャネルごとに共通Attentionを適用するため、おそらく1D CNN側で各チャネルの時系列特徴分布が全チャネルで同じような分布になるように学習が進むのだと推測されます。
※観点は異なっているが、時系列の特徴分布は同じというイメージ。
1D CNNは局所的な時系列特徴抽出、Attentionで時系列全体の関係性を取得、1D CNNは局所特徴抽出に加えてAttention用分布調整も行っているという感じでしょうね。
SE × Attention
Attention Is All You NeedのSelf-Attentionをご存じの方は1D CNNやった後にC×時系列情報の行列でQ, K作成してSelf-Atentionすれば手っ取り早くないか?と思う方がいらっしゃるかもしれません。
まずSelf-Attentionについては簡単にまとめると以下のような感じです。
テキストシーケンスの例で書いてますが、テキストのところをチャネル、Embeddingのところを時系列情報に置き換えてみてください。
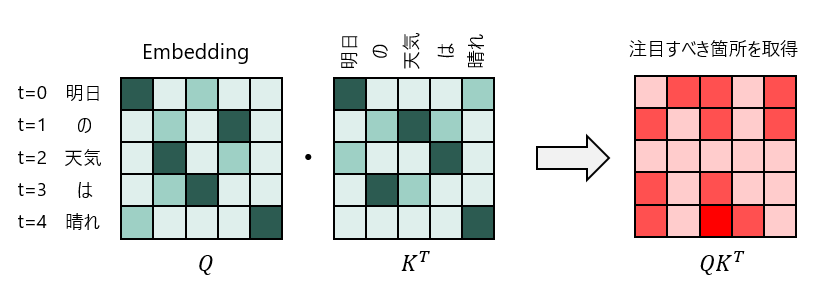
これを見るとSelf-Attentionをするとチャネル方向と時系列方向の関係を一気に取得できることがわかります。
チャネル方向と時系列を同時に双方向から見て関係性を取得できるというのは素晴らしいことなんですが、計算量が多いという問題があります。
処理時間や計算リソースが潤沢にあればSelf-Attentionでよいのですが制約がある状況ではそうもいきません。
SE×Attentionは計算量を抑えつつ、Self-Attentionと似たような結果を(おそらく)得られるため、制約がある状況で効いてきます。
SEによってチャネル方向の関係をつかみ、時系列のみAttentionによって時系列の関係性をつかんでるため、2つを組み合わせることで疑似的にSelf-Attentionと同様なことが行われています。
まとめ
時系列データから取得する特徴量として時系列局所特徴、チャネル方向関係性、時系列全体関係性があることがわかり、それぞれ取得するためには1D CNN, SE, Attentionが使われるということがわかりました。
時系列に限らずですが、タスクに応じたモデルを構築する際の考え方としては、CNNといった各モジュールについて本質的な役割を理解して役割単位で構築していくというのが、より精度の高いモデルを構築するうえで重要ですね。
最後までご覧いただきありがとうございました。
