今回はKaggleで2025年に開催された”BYU – Locating Batterial Flagellar Motors 2025″の1位の解法について解説していこうと思います。
解説の前にコンペ概要と評価指標についても説明しておきます。
コンペリンク:
BYU – Locating Bacterial Flagellar Motors 2025 | Kaggle

コンペ概要
入力データはtomogramというCTのように複数の断面スライスが積み重なった3D画像です。
各バクテリア毎にtomogramがあり、tomogramから鞭毛モーターの位置を検出するタスクとなります。
位置はMotor Axis 0(z), Motor Axis 1(y), Motor Axis 2(x)で表現され、モーターが存在しない場合はそれぞれに-1という値をセットします。
評価指標
評価指標は以下のようになってます。
予測した位置と正解のユークリッド距離を算出し、ユークリッド距離が1000Å(0.1μm)以下であればTPをカウント、1000Åより大きければFNをカウント。
この評価指標で注意するポイントとしては、FP(モーターが無いものを有ると検知)よりもFN(モーターが有るものを無いと検知)の方がペナルティが大きいという点です。
今回、β=2であるためFNを出すことはFPを出すことの4倍影響を受けます。
データの内容にもよりますが、基本的にモーターは存在する前提で予測させた方がよさそうということになります。(FN出すよりFP出した方がましという考え方)
1位解法概要
コンペ概要と評価指標を踏まえて早速1位解法の解説に入っていきます。
1位の方の解法リンクは以下になります。(適宜図を引用させていただいてます。)
1st Place – 3D U-Net + Quantile Thresholding | Kaggle
前処理
主要な内容としては以下の図に示した通りとなります。
- 外部データを加えることによって学習データ量を増加
- napariという3Dアノテーションツールを使用し、データを直接確認してラベル修正を実施
- もし、ラベル修正してもモーターが無いものについては学習データから除去
- Gaussian Heat mapでラベル付け ※Gaussian Heat map概要については図を参照
- ダウンサンプリングして解像度を8倍低下
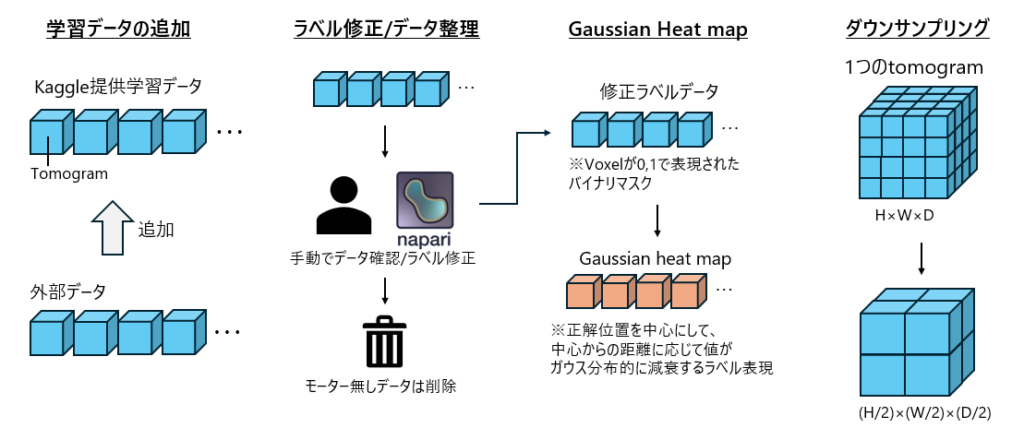
2でモーター無しデータを削除している理由としては、評価指標の最後で述べたようにFN(モーターがあるのに無い)を回避するためだと考えられます。
4, 5については、ピンポイントで位置を当てにいこうとすると難易度が高いためおおよその位置を当てにいくための処理になります。
以下は1位の方が解法と一緒に載せてくれていた図となるんですが、赤い丸の範囲がTPと判定される範囲となります。
見ていただくとわかるように、TPと判定される範囲がけっこう広いため、おおよその位置を当てられれば良いというのがわかります。
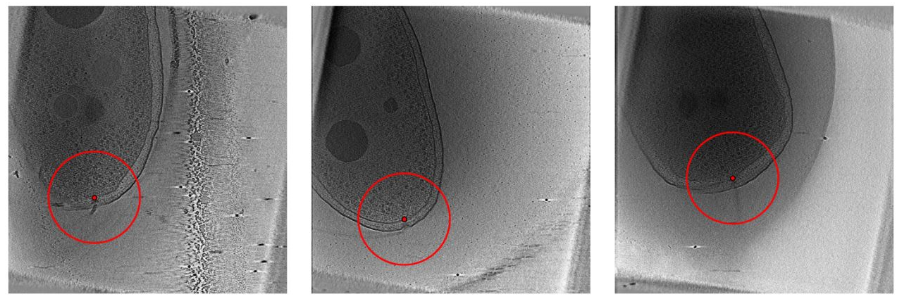
※実際の解法説明より引用
モデル
モデルは”3D-Unetのようなもの”とのことです。(下図参照)
Encoder部には以下リンク先にあるResNet200のpre-trained済みのものを使用。
https://github.com/kenshohara/3D-ResNets-PyTorch
当初はResNet101を使用していたらしいですが、モデルの表現力が高いほど性能が良かったそうです。
Decoder部には単体のdeconvolutionブロックを入れ、そのあとはすぐSegmentation head(logits予測のhead)。
図には表現されてないですが、正則化のためにStochastic dropoutが適用されているそうです。

Loss計算
Lossの計算にはSmoothBCE lossを使用。※SmoothBCE lossは重要ポイントではないので省略。
以下の図で濃い色はGT、GTの手前の薄い色のBoxが予測値。(おそらく)
前処理であったようにGTは3DのGaussian Heat mapとなってます。
中心の一番大きいBoxがメインのSegmentation Headであり解像度が高いものです。
ここで工夫されている点としては中間層を抜き出したAux HeadとMax PoolされているHeadだと思います。
Aux Headについては後述の補足のところをご参照ください。補足の箇所にも記載してますが、Aux Headでlossを計算している理由としてはおそらく層の深いところへ誤差伝播させるためです。
Max poolさせたものでlossを計算しているのは、おおよその位置を当てるための学習をさせようとしているものと考えられます。
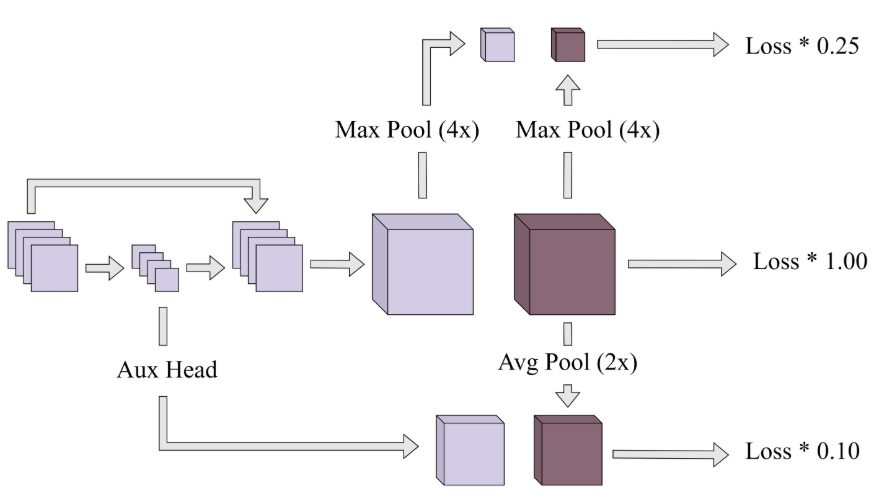
【補足】Aux Headについて
Deep supervisionというテクニックがあり、これは隠れ層に分類器をくっつけて学習中に中間層でも出力させることで層の深いところも学習するもの。
このときの分類器がAux Head(Auxiliary Head)。
Augmentation
強めのAugmentationをかけてます。
Augmentationの内容は以下の通りです。
- Mixup(100%)
- Rescale/Zoom(100%)
- Rotate90/180/270(100%)
- Axis Flips(100%)
- Axis Swap(100%)
- Coarse Dropout(50%)
- Color inversion(25%)
- Simple Cutmix(15%)
強めのAugmentationをかけたので400epoch学習させても過学習はしなかったが、CPU上では上記Augmentationを回すと時間が不足したため、Rescale以外はGPU上で実行。
推論
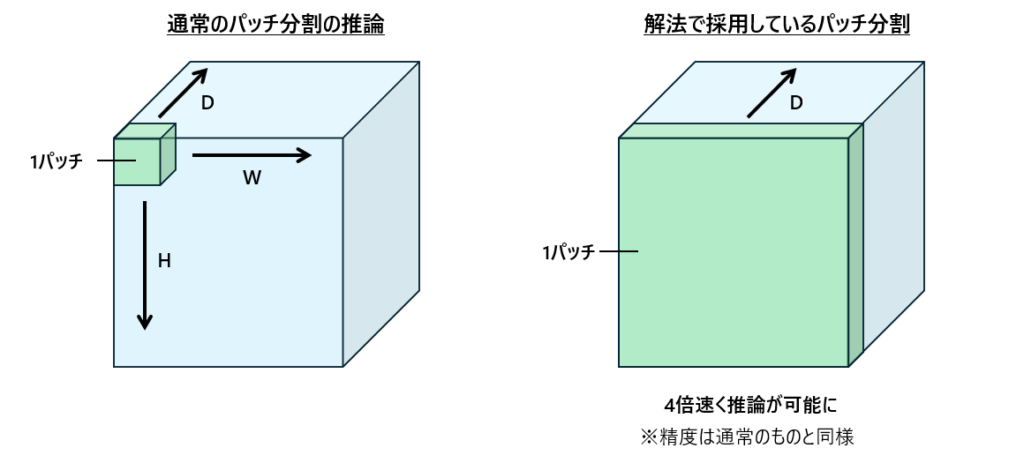
3Dデータそのままだとメモリに載らずパッチ分割して推論。
※パッチ分割:データを指定のサイズで区切り(パッチ)、それぞれを推論してマージ
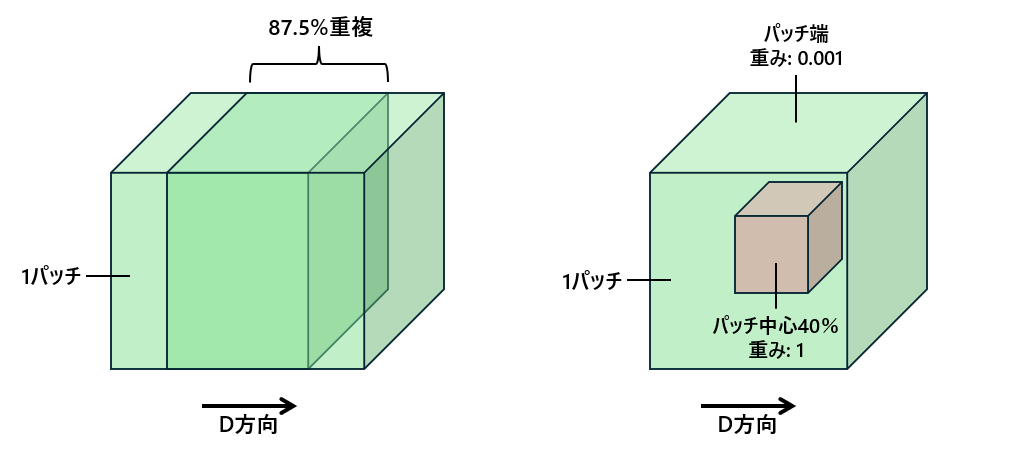
最終的に下図の右側にあるようにH, W方向のパッチサイズを大きくしてD方向にのみスライドするようにしたことで精度維持したまま推論速度を4倍にすることができた。
推論速度を上げたことによって、TTA(Time Test Augmentation)や下図に示すようにパッチスライド時の重なりを87.5%と厚くしても時間が収まった。
推論時の重みづけについてはパッチ中心40%は1, それ以外の端の部分については0.001の重みとしている。
端の部分は中心に比べたら周辺の文脈が減り、推論結果の信頼度が低いため0.001の重みだと考えられる。
アンサンブル
- Seed Ensembleを行い、8seedでensemble。
※同一モデル異なるseedで学習させ、8つのモデルを用意。 - 各モデルの出力にSigmoidをかけて、それぞれ足し合わせ
PostProcess
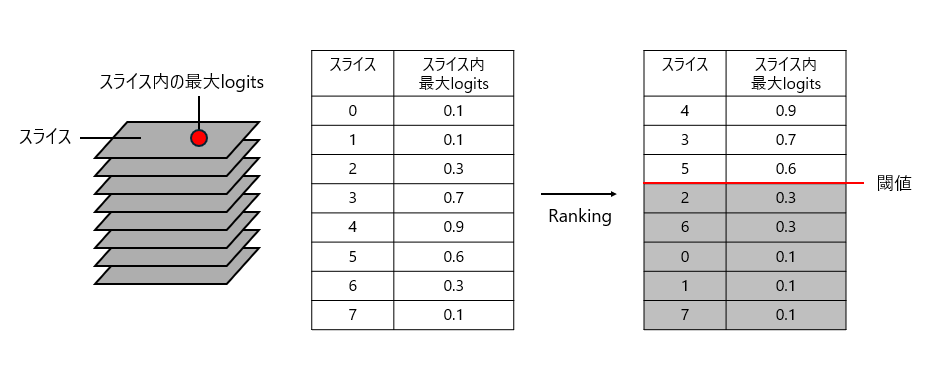
- 各スライスにおける各pixelのlogitsを確認して、最大logitsを取得。
- logitsの値に応じてスライスをランク付け
- ランク上位のスライスを取得して、各スライスにおける最大logitsのpixel座標を統合してx, y, zを取得※
※ランク上位の判定には分位閾値(quantile threshold)を使用。
※x, y, zは複数座標の重心なのかどうか不明のため、次回の実装コード解説で確認
CVは4分割にしたらLBと相関が取れるようになった。
まとめ
最後まで読んでいただき、ありがとうございます。
データを外から持ってきたり、手動でアノテーションしていたりと執念が感じられる内容でした。
また、データを捨てる、モデルの学習で予測する位置を大雑把にさせるなど、評価指標に合わせて過検知寄りにしつつもTPは取りに行ける工夫が詰め込まれており、非常に面白い解法でした。
次回は実際のコードを確認して、どのように実装されているか解説する予定です。

