
今回はKaggle BYU 2025 1位解法の3D Unet Decoder部の実装について解説していきます。
コンペ:BYU – Locating Bacterial Flagellar Motors 2025 | Kaggle
参考リポジトリ:GitHub – brendanartley/BYU-competition: 1st place solution for the BYU Locating Bacterial Flagellar Motors Competition
前回のEncoder(Resnet200)を踏まえた内容となっているため、前回記事をまだご覧になっていない方は一度目を通していただくことを推奨します。
Encoder実装解説:Cryo-ET 鞭毛モーターの3D検出 | Kaggle BYU 2025 1位解法コード解説 (3D Unet Encoder部)
Decoder全体
ファイル※:src/models/layers/unet3d.py
※記事最初に記載してある参考リポジトリのもの
import torch
import torch.nn as nn
import torch.nn.functional as F
from monai.networks.blocks import UpSample
class ConvBnAct3d(nn.Module):
def __init__(
self,
in_channels,
out_channels,
kernel_size,
padding: int = 0,
stride: int = 1,
norm_layer: nn.Module = nn.BatchNorm3d,
act_layer: nn.Module = nn.ReLU,
):
super().__init__()
self.conv= nn.Conv3d(
in_channels,
out_channels,
kernel_size,
stride=stride,
padding=padding,
bias=False,
)
self.norm = norm_layer(out_channels)
self.act= act_layer(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.norm(x)
x = self.act(x)
return x
class DecoderBlock3d(nn.Module):
def __init__(
self,
in_channels,
skip_channels,
out_channels,
norm_layer: nn.Module = nn.BatchNorm3d,
upsample_mode: str = "deconv",
scale_factor: int = 2,
):
super().__init__()
self.upsample = UpSample(
spatial_dims= 3,
in_channels= in_channels,
out_channels= in_channels,
scale_factor= scale_factor,
mode= upsample_mode,
)
self.conv1 = ConvBnAct3d(
in_channels + skip_channels,
out_channels,
kernel_size= 3,
padding= 1,
norm_layer= norm_layer,
)
self.conv2 = ConvBnAct3d(
out_channels,
out_channels,
kernel_size= 3,
padding= 1,
norm_layer= norm_layer,
)
def forward(self, x, skip: torch.Tensor = None):
x = self.upsample(x)
if skip is not None:
x = torch.cat([x, skip], dim=1)
x = self.conv1(x)
x = self.conv2(x)
return x
class UnetDecoder3d(nn.Module):
def __init__(
self,
encoder_channels: tuple[int],
skip_channels: tuple[int] = None,
decoder_channels: tuple[int] = (256, 128, 64, 32, 16),
scale_factors: tuple[int]= (2,2,2,2,2),
norm_layer: nn.Module = nn.BatchNorm3d,
attention_type: str = None,
intermediate_conv: bool = False,
upsample_mode: str = "nontrainable",
):
super().__init__()
self.decoder_channels= decoder_channels
if skip_channels is None:
skip_channels= list(encoder_channels[1:]) + [0]
# Build decoder blocks
in_channels= [encoder_channels[0]] + list(decoder_channels[:-1])
self.blocks = nn.ModuleList()
for i, (ic, sc, dc, sf) in enumerate(zip(
in_channels, skip_channels, decoder_channels, scale_factors,
)):
self.blocks.append(
DecoderBlock3d(
ic, sc, dc,
norm_layer= norm_layer,
upsample_mode= upsample_mode,
scale_factor= sf,
)
)
def forward(self, feats: list[torch.Tensor]):
res= [feats[0]]
feats= feats[1:]
for i, b in enumerate(self.blocks):
skip= feats[i] if i < len(feats) else None
res.append(
b(res[-1], skip=skip),
)
return res
class SegmentationHead3d(nn.Module):
def __init__(
self,
in_channels,
out_channels,
scale_factor: tuple[int] = (2,2,2),
):
super().__init__()
self.conv= nn.Conv3d(
in_channels, out_channels,
kernel_size = 3, padding = 1,
)
self.upsample = UpSample(
spatial_dims= 3,
in_channels= out_channels,
out_channels= out_channels,
scale_factor= scale_factor,
mode= "nontrainable",
)
def forward(self, x):
x = self.conv(x)
x = self.upsample(x)
return x
if __name__ == "__main__":
m= UnetDecoder3d(
encoder_channels=[128, 64, 32, 16, 8],
)
m.cuda().eval()
with torch.no_grad():
x= [
torch.ones([2, 128, 1, 4, 4]).cuda(),
torch.ones([2, 64, 2, 8, 8]).cuda(),
torch.ones([2, 32, 4, 16, 16]).cuda(),
torch.ones([2, 16, 8, 32, 32]).cuda(),
torch.ones([2, 8, 16, 64, 64]).cuda(),
]
z = m(x)
print([_.shape for _ in z])ここで実装している内容のイメージを図1に示します。
※3次元×チャネルで表現しようかと思いましたが、図が巨大になりそうだったためチャネルの表現を優先しました。図に記載されているBoxの幅がチャネルを示しており、高さが3次元のうちのどこか1次元(D or H or W)のサイズを示していると思ってください。
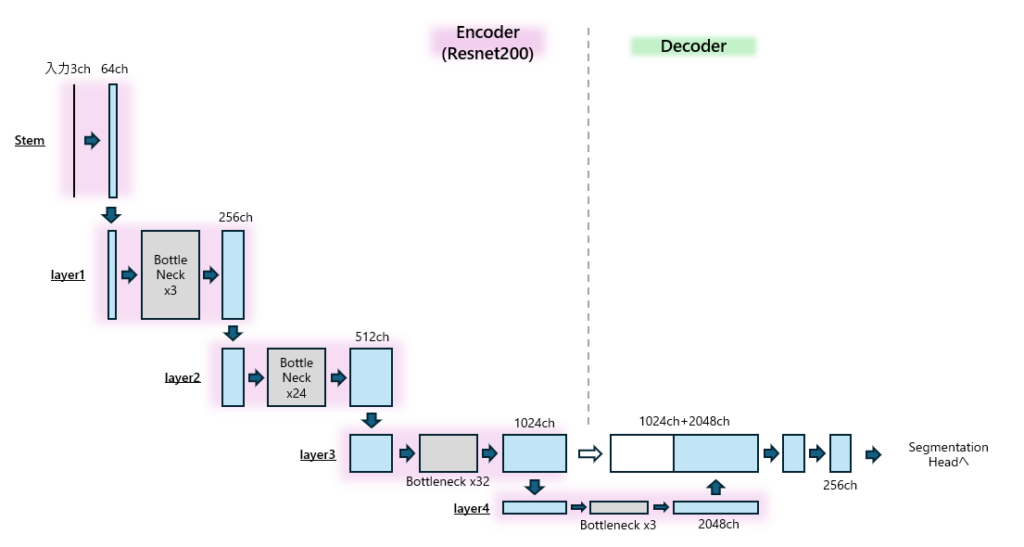
図の右側がDecoderになります。Encoderの内容も絡んでくるのでEncoderも一緒に載せてます。Unetの形が完成してますね。
Encoderの各段の左端にStemやlayer1, 2,…と書いてるのは前回のEncoderの話になります。
前回のEncoderの話は重かったと思いますが、Decoderについては正直なところ図1を見ながらコードを読めばほぼ完結します:)
ConvBnAct3d
ここは畳み込み層定義してるだけなので特に述べることはないです。
BN入れてるのでbias=Falseにしているというのは前回のEncoderの”conv3x3x3″のところで述べているので気になる方はそちらをご覧ください。
/Cryo-ET 鞭毛モーターの3D検出 | Kaggle BYU 2025 1位解法コード解説 (3D Unet Encoder部)
class ConvBnAct3d(nn.Module):
def __init__(
self,
in_channels,
out_channels,
kernel_size,
padding: int = 0,
stride: int = 1,
norm_layer: nn.Module = nn.BatchNorm3d,
act_layer: nn.Module = nn.ReLU,
):
super().__init__()
self.conv= nn.Conv3d(
in_channels,
out_channels,
kernel_size,
stride=stride,
padding=padding,
bias=False,
)
self.norm = norm_layer(out_channels)
self.act= act_layer(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.norm(x)
x = self.act(x)
return xDecoderBlock3d
ここも大したことないです。図1のDecoderの1段分の処理を定義してます。
- upsampleのところでチャネルサイズはそのままで、のサイズをscale_factorの値に応じて拡大
- conv1のところで本流からのデータとEncoderからスキップしてきたデータを結合したものを畳み込み
- conv2で再度畳み込み
upsample_modeは最終的に”deconv”が渡されます。※
※DecoderBlock3dではデフォルトが”deconv”。
DecoderBlock3dが呼ばれているUnetDecorder3dではデフォルト”nontrainable”。
そのためnontrainableかと思いきや、次回解説するところになりますがUnetDecorder3dを呼び出して3D Unetを完成させるところでは”deconv”を渡してました。
class DecoderBlock3d(nn.Module):
def __init__(
self,
in_channels,
skip_channels,
out_channels,
norm_layer: nn.Module = nn.BatchNorm3d,
upsample_mode: str = "deconv",
scale_factor: int = 2,
):
super().__init__()
self.upsample = UpSample(
spatial_dims= 3,
in_channels= in_channels,
out_channels= in_channels,
scale_factor= scale_factor,
mode= upsample_mode,
)
self.conv1 = ConvBnAct3d(
in_channels + skip_channels,
out_channels,
kernel_size= 3,
padding= 1,
norm_layer= norm_layer,
)
self.conv2 = ConvBnAct3d(
out_channels,
out_channels,
kernel_size= 3,
padding= 1,
norm_layer= norm_layer,
)
def forward(self, x, skip: torch.Tensor = None):
x = self.upsample(x)
if skip is not None:
x = torch.cat([x, skip], dim=1)
x = self.conv1(x)
x = self.conv2(x)
return x
UnetDecoder3d
Decoder全体の作成です。ここはチャネルサイズが厄介ですがそこだけです。
チャネルを格納してるリスト(&タプル)について、それぞれどのような値が入ってるか記載しておきます。登場順で記載してます。
※中間情報については通常の太さ、Decoder構築する際に使用する値は太字で記載してます。
- decoder_channels: (256, ) ※1
- encoder_channels: [2048, 1024, 512, 256, 64] ※2
- list(encoder_channels[1:]): [1024, 512, 256, 64]
- skip_channels: [1024, 512, 256, 64, 0]
- list(decoder_channels[:-1]: ()
- in_channels: [2048]
※1.デフォルト値の(256, 128, 64, 32, 16)ではないことに注意。次回のモデル完成のところで渡しているものを確認。
※2.次回のモデル完成のところで話しますが、前回のEncoderで取得したチャネルのリストが順序反転して入ってきます。
__init__の最後のところで上記のチャネルリストとscale_factorをDecoderBlock3dに渡して各ブロックを生成してますね。
ブロック生成時にforループしてますが、zipによって一番短いイテラブルで打ち切られるのでin_channels=2048, skip_channels=1024, decoder_channels=256の組み合わせ1回だけでループ終了します。
forwardについて、引数のfeatsはEncoderでの各layerの出力(torch.Tensor)のリストです。
“b(res[-1], skip=skip)”で前段ブロックの出力res[-1]とEncoderからスキップされた出力skipをDecoderBlock3dのオブジェクトに渡してる、すなわちDecoderBlock3dのforwardの引数x, skipにそれぞれ入っていってます。
res.append(b(略))のところではDecoderの各ブロック(各段)の出力x(torch.Tensor)がリストに追加されているということになります。
なぜここで最終出力xのみではなくDecoder各段の出力をリストとして取得しているかについては、loss計算でAux HeadやMax Pool Head用に途中出力を取り出しやすくするためになります。
Aux Head等については解法解説の”Loss計算”の箇所をご覧ください。
Cryo-ET 鞭毛モーターの3D検出 | Kaggle BYU 2025 1位解法解説
class UnetDecoder3d(nn.Module):
def __init__(
self,
encoder_channels: tuple[int],
skip_channels: tuple[int] = None,
decoder_channels: tuple[int] = (256, 128, 64, 32, 16),
scale_factors: tuple[int]= (2,2,2,2,2),
norm_layer: nn.Module = nn.BatchNorm3d,
attention_type: str = None,
intermediate_conv: bool = False,
upsample_mode: str = "nontrainable",
):
super().__init__()
self.decoder_channels= decoder_channels
if skip_channels is None:
skip_channels= list(encoder_channels[1:]) + [0]
# Build decoder blocks
in_channels= [encoder_channels[0]] + list(decoder_channels[:-1])
self.blocks = nn.ModuleList()
for i, (ic, sc, dc, sf) in enumerate(zip(
in_channels, skip_channels, decoder_channels, scale_factors,
)):
self.blocks.append(
DecoderBlock3d(
ic, sc, dc,
norm_layer= norm_layer,
upsample_mode= upsample_mode,
scale_factor= sf,
)
)
def forward(self, feats: list[torch.Tensor]):
res= [feats[0]]
feats= feats[1:]
for i, b in enumerate(self.blocks):
skip= feats[i] if i < len(feats) else None
res.append(
b(res[-1], skip=skip),
)
return resSegmentationHead3d
最後にSegmentationHeadです。
ここに関しては畳み込みとupsampleしてるだけなので特筆すべきことは無いです。
class SegmentationHead3d(nn.Module):
def __init__(
self,
in_channels,
out_channels,
scale_factor: tuple[int] = (2,2,2),
):
super().__init__()
self.conv= nn.Conv3d(
in_channels, out_channels,
kernel_size = 3, padding = 1,
)
self.upsample = UpSample(
spatial_dims= 3,
in_channels= out_channels,
out_channels= out_channels,
scale_factor= scale_factor,
mode= "nontrainable",
)
def forward(self, x):
x = self.conv(x)
x = self.upsample(x)
return xまとめ
DecoderについてはEncoderから渡されるスキップされるデータがどうなってるかを把握できてればすんなり頭に入る内容だったかと思います。
次回はEncoderとDecoderを組み合わせつつ、学習時のloss計算用Headを作ったり、AugmentationやTTAを入れたりしてモデルを完成させる箇所について解説をしていきます。
