
Kaggle BYU 2025 1位解法について、いよいよ最後の推論パートとなります。
解法解説からは読み取れなかった内容を確認できたため、そちらについて重点的に見ていこうと思います。
コンペ:BYU – Locating Bacterial Flagellar Motors 2025 | Kaggle
参考リポジトリ:GitHub – brendanartley/BYU-competition: 1st place solution for the BYU Locating Bacterial Flagellar Motors Competition
推論の流れ
詳細見る前に推論のざっくりとした流れをまとめておきます。
推論コードはリポジトリではなくkaggle notebook(こちら)にありました。環境はT4×2です。
- DDPで分割推論するために、1GPUで処理する内容(モデル割り当て等)を1セル内で作成。
処理内容をddp.pyというファイルとして書き出しており、処理内容の概要は以下。
※詳細は後ほど- 1GPUに複数モデルをロード ※2の話と合わせて説明
- DataLoader作成
- パッチ推論の準備&パッチ推論
- 推論結果の保存
- 8モデルを2組(4, 4)に分けて、4モデルずつDDPで推論。
- 最終出力(座標)を取得するためのPostProcessing
各ポイントについてそれぞれ見ていきます。
パッチ推論 (MONAI sliding_window_inference)
パッチ推論はsubmitされているnotebookでは以下の部分が該当します。
roi_sizeやroi_weight_mapが肝となる部分のため後述します。
値について補足しておくと、img_sizeが(128, 674, 674)であり、roi_sizeが(64, 674, 674)となります。
# ========== Inference Loop ===========
preds_final= []
with torch.no_grad():
# ROI weight map (downweights edge predictions)
pct = 0.30 # 30% edge
z, h, w = c.img_size
z_margin = int(z * pct)
h_margin = int(h * pct)
w_margin = int(w * pct)
roi_weight_map = torch.ones((z, h, w), device=rank) # Initialize everything as 1.0
roi_weight_map[:z_margin] = 1e-3 # Top edge
roi_weight_map[-z_margin:] = 1e-3 # Bottom edge
roi_weight_map[:, :h_margin] = 1e-3 # Left edge
roi_weight_map[:, -h_margin:] = 1e-3 # Right edge
roi_weight_map[:, :, :w_margin] = 1e-3 # Front edge
roi_weight_map[:, :, -w_margin:] = 1e-3 # Back edge
for batch in tqdm(test_dl):
with autocast(cfg.device.type):
try:
tomo_id= batch.pop("tomo_id")[0]
batch = batch_to_device(batch, device=rank)
batch["input"]= batch["input"].float()
# Sliding window
preds= None
for midx, row in enumerate(models):
_preds = sliding_window_inference(
inputs= batch["input"],
roi_size= row["cfg"].roi_size,
predictor= row["model"],
roi_weight_map= roi_weight_map,
**vars(row["cfg"].infer_cfg)
)[0, 0, ...]
_preds= torch.sigmoid(_preds)
if preds is None:
preds = _preds
else:
preds += _preds1データをwindowサイズに分割しパッチという単位に分け、各パッチを推論して最後に統合して出力結果を得るという、パッチ推論もしくはSliding Window Inferenceがあります。
これを利用する目的としては、大きいデータを処理できるように分割するというのもあると思いますが、今回はself-ensemble的な目的があると思います。
以下の図1に1パッチあたりの処理イメージ、図2にwindowをスライドさせて出力を得るイメージを示してます。
MONAIというPytorchベースの医療データ処理のフレームワークがあり、MONAIにあるsliding_window_inferenceという処理でパッチ推論が行われています。
先ほどのコードでもありましたが、以下の図に示しているroi_sizeは取得する1パッチ分のサイズであり、roi_weight_mapはパッチの出力結果にかけ合わせる重みのマップとなります。
重みのマップは解法で説明があり、コードからもわかりますが、中心40%の重みが1であり、それ以外は0.001になってます。
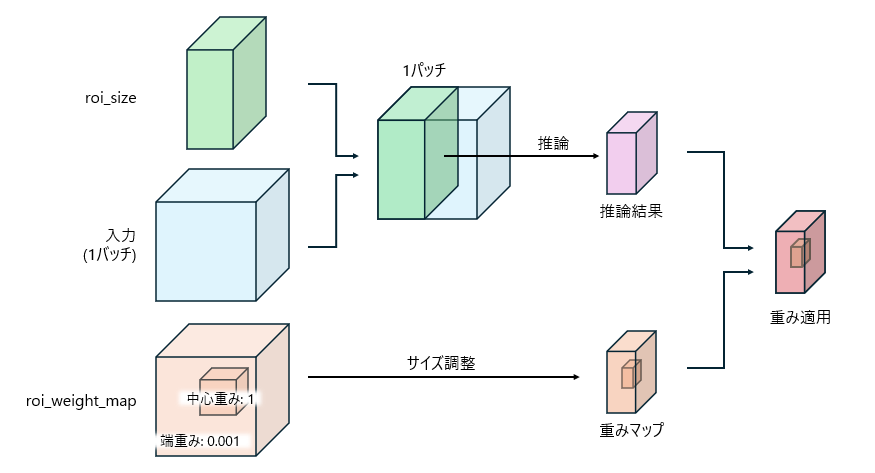
図1に示す通り、まずは入力データからパッチサイズ分のデータに対して推論を行います。
roi_weight_mapの構造を残しつつ推論結果に合わせて重みマップのサイズを調整して、推論結果に掛け合わせています。
これが1パッチ分の処理となります。
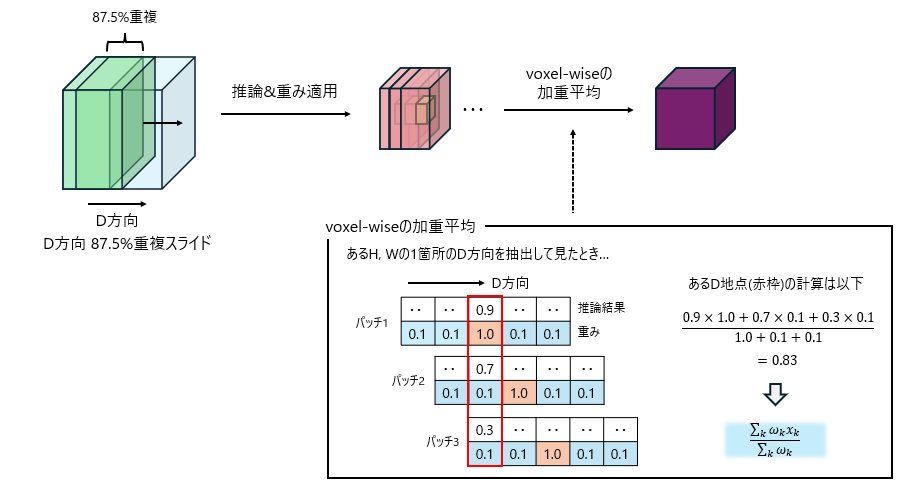
図2はwindowをスライドさせて、各パッチの推論結果を出力結果として統合していく様子を示したものとなります。
パッチが重複しているので、統合する際には同じ位置のvoxel同士(voxel-wise)で加重平均を取り統合してます。
加重平均のイメージについては図に示している通りです。
ここまでがパッチ推論の流れとなります。パッチで重複している範囲が87.5%と広く、同じところを何度も推論することになるのでself-ensembleとして機能しているのだと思います。
DDPによる分割推論
こちらは精度上げるためというよりも推論速度を上げるためのものとなります。
プロセスの話があってややこしいので、まずは図3を見てください。実際に行われている内容を図示したものとなります。
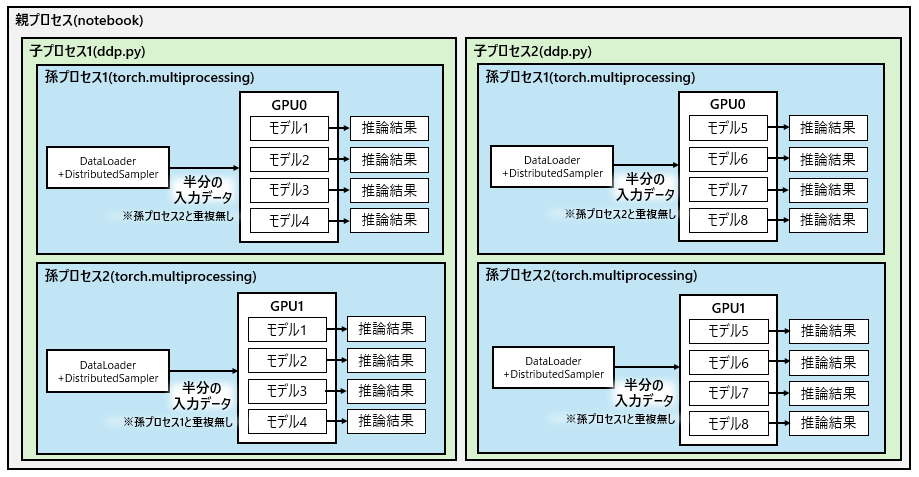
流れとしては、
- 親プロセス(notebook)がDDP推論を行うddp.pyファイル(子プロセス)を起動
- ddp.pyファイルがGPUの数だけ孫プロセスを起動
- 孫プロセスの中身はモデルロードやパッチ推論といった、通常の推論プロセス
- DistributedSamplerによって孫プロセス同士で推論データがかぶらないようにデータ分割されるため、それぞれの孫プロセスで分担して推論を実行(理論上2倍速)
図を見ていただくと、子プロセス1と子プロセス2があると思いますが、これはddp.pyを2回実行してることを意味してます。子プロセスは同期処理となっているため、子プロセス1が終わってから子プロセス2に進むという流れになってます。※GPUが空いてないため同期処理マスト
子プロセスが2回行われる理由については、8個のモデルで推論させたいが、GPU1つに対してモデル4つが限界であるため、2回に分けて処理してるみたいです。
もしかしたら、もっと多くのモデルで推論させたかったが、8個が時間的にぎりぎりだったから8個に絞ったということかもしれませんね。
コード抜粋
DDP分割推論の箇所で、コードの一部を抜粋します。
■Markdownで”Infer”と書かれた直後のセル
%%writefile ddp.py
...
def run_inference(rank, world_size):
# ========== Config ==========
if is_kaggle():
c= SimpleNamespace()
...
c.script_idx= int(os.environ.get("SCRIPT_IDX"))
...
...
# ========== Models ===========
models = []
mpaths= sorted(glob.glob(c.model_dir))
total_models= len(mpaths)
mid= len(mpaths)//2
if c.script_idx == 0:
mpaths= mpaths[:mid]
else:
mpaths= mpaths[mid:]
...
def run_DDP(run_fn, world_size):
mp.spawn(run_fn, args=(world_size,), nprocs=world_size, join=True)
...
def run_all(rank, world_size):
print(f"Running DDP code on rank {rank}.")
setup(rank, world_size)
c, preds= run_inference(rank, world_size)
cleanup(rank)
return
if __name__ == "__main__":
...
n_gpus = torch.cuda.device_count()
print(f"total GPUs: {n_gpus}")
world_size = n_gpus
run_DDP(run_all, world_size)“%%writefile ddp.py”としているので、GPUへのモデルロードやパッチ推論等を行っている内容がddp.pyとして書き出されます。すなわち、このセルの中身が後ほど子プロセスとして実行される内容となります。
最初のdef run_inferenceにモデルロードやパッチ推論等のメインの処理、すなわち孫プロセスの内容が書かれてます。
中盤のModelsというところを見ていただくと、c.script_indexの値次第で8モデルの前半4モデル(mpaths[:mid])、または後半4モデル(mpaths[mid:])が取得されることがわかります。
続いて、def run_DDP(run_fn, world_size)のところを見ていただくと、mp.spawnというのがあり、ここが孫プロセスを起動するところとなります。nprocsの値に応じた数の孫プロセスを起動させ、孫プロセスのidxがrun_fnの第一引数へと渡されます。
この孫プロセスidxが度々出てくるrankの元であり、GPU選択にも使用されてます。
run_fnは何か?という話になると思いますが、最後の部分を見るとdef run_all(rank, world_size)であることがわかります。def run_allは孫プロセスの中身であるdef run_inferenceを実行するものとなってます。
■上記セル以降
import time
start_time= time.time()
kicr = "true" if os.getenv('KAGGLE_IS_COMPETITION_RERUN') else ""
kub = "true" if 'KAGGLE_URL_BASE' in os.environ else ""
!KAGGLE_IS_COMPETITION_RERUN={kicr} KAGGLE_URL_BASE={kub} SCRIPT_IDX=0 python ddp.py!KAGGLE_IS_COMPETITION_RERUN={kicr} KAGGLE_URL_BASE={kub} SCRIPT_IDX=1 python ddp.pyこちらが親プロセス(notebook)からddp.pyを実行するところ、すなわち子プロセスを実行するところです。
それぞれ環境変数を設定したうえでddp.pyファイルを実行してます。SCRIPT_IDXがそれぞれ0と1になっているところがポイントです。
先ほどc.script_idx(=SCRIPT_IDX)次第で8モデルの前半4つか後半4つを取得するところがあったと思いますが、ここで設定してる内容となります。
SCRIPT_IDXを0で実行したddp.py(子プロセス)では前半4つでDDP分割推論が実行され、SCRIPT_IDXを1で実行したddp.pyでは後半4つでDDP分割推論が実行される というものになってます。
PostProcess
ついに最後の仕上げです。
ここまでくるとコードについては特に語れることが無いため参考までに貼っておくだけにしておきます。
import json
import glob
import pandas as pd
import torch
# =========== Load infer metadata ==========
d= []
fpaths= sorted(glob.glob("/tmp/working/*.json"))
for fpath in fpaths:
# Load json
with open(fpath, "r") as f:
metadata= json.load(f)
metadata= metadata | {"fpath": fpath.replace(".json", ".pt")}
d.append(metadata)
df = pd.DataFrame(d)
# Sanity check
# DDP might predict 2x for same tomo
df = df.groupby('tomo_id', as_index=False).agg({
'tomo_id': 'first',
'script_id': 'first',
'z_shape': 'first',
'y_shape': 'first',
'x_shape': 'first',
'fpath': lambda x: list(set(x)),
})
display(df)from tqdm import tqdm
import numpy as np
# ========== Ensemble volumes ===========
sub_rows= []
for i, row in tqdm(df.iterrows(), total=len(df)):
row= row.to_dict()
# Ensemble
arr= []
for f in row["fpath"]:
tmp= torch.load(f, weights_only=False)
arr.append(tmp)
arr= torch.stack(arr, axis=0)
arr= torch.sum(arr, axis=0) # Mean ensemble
# arr= arr.median(dim=0).values # Median ensemble
# arr= (arr.clamp(min=0.01).log().mean(dim=0)).exp() # Geometric mean ensemble
# Argmax
coords = torch.argmax(arr)
coords = torch.unravel_index(coords, arr.shape)
coords = (
(coords[0].item() + 0.5) / arr.shape[0],
(coords[1].item() + 0.5) / arr.shape[1],
(coords[2].item() + 0.5) / arr.shape[2],
)
# Add
sub_rows.append({
"tomo_id": row["tomo_id"],
"z": coords[0] * row["z_shape"],
"y": coords[1] * row["y_shape"],
"x": coords[2] * row["x_shape"],
"max": torch.max(arr).item(),
})
sub= pd.DataFrame(sub_rows)
display(sub)# Apply Threshold
cutoff= sub['max'].quantile(QUANTILE_THRESHOLD)
sub.loc[sub["max"] <= cutoff, ["z", "y", "x"]]= -1.0
print("="*25)
print("threshold:", QUANTILE_THRESHOLD)
print("cutoff:", cutoff)
print("="*25)
# Format sub
col_map= {
"z": "Motor axis 0",
"y": "Motor axis 1",
"x": "Motor axis 2",
}
sub= sub.rename(columns=col_map)
sub= sub[["tomo_id", "Motor axis 0", "Motor axis 1", "Motor axis 2"]]
sub.to_csv("submission.csv", index=False)
print(sub)
clean_working("/tmp/images/")
clean_working("/kaggle/working/")最後に行われている内容を図4に示します。
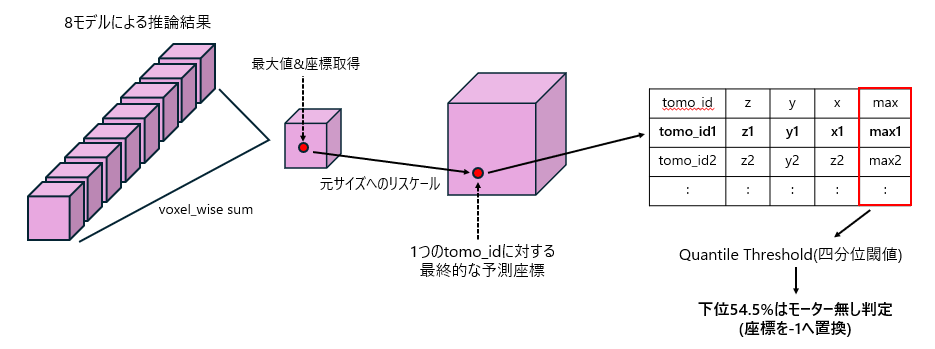
8モデルによる推論結果をvoxel単位で足し合わせて、最大値の座標とその値を取得。座標は元の入力データのサイズに合わせてリスケール。
上記によりtomo_id一つ当たりの予測座標と最大値の取得完了。
全tomo_idの予測座標と最大値を取得したら、最大値を用いてQuantile thresholodingを行い、下位54.5%のものはモーター無しと判定して座標を-1に置換。
最終的な結果をsubmit。
まとめ
以上で推論、そしてBYU2025 1位解法の全てのコード確認が完了しました。
解法解説であったQuantile thresholdやパッチ推論といったものはたしかに精度向上に重要だったと思います。
基本的過ぎて解法では述べられてなかったのかもですが、個人的には推論高速化も重要な内容であると感じました。
推論速度を上げられたことによって、厚めの重複パッチや8seed ensembleといったことができていると思うため、外せない要素だと思いました。
全体の振り返りは別記事で改めてまとめる予定です。
最後までご覧いただきありがとうございました。
