
前回, 前々回でKaggle BYU 2025 1位解法のEncoderとDecoderの実装について見てきましたが、今回それらを統合させて完成させる箇所の実装について解説していきます。
コンペ:BYU – Locating Bacterial Flagellar Motors 2025 | Kaggle
参考リポジトリ:GitHub – brendanartley/BYU-competition: 1st place solution for the BYU Locating Bacterial Flagellar Motors Competition
前回, 前々回のEncoder(Resnet200)を踏まえた内容となっているため、まだご覧になっていない方は一度目を通していただくことを推奨します。
Encoder実装解説:Cryo-ET 鞭毛モーターの3D検出 | Kaggle BYU 2025 1位解法コード解説 (3D Unet Encoder部)
Decoder実装解説:Cryo-ET 鞭毛モーターの3D検出 | Kaggle BYU 2025 1位解法コード解説 (3D Unet Decoder部)
モデル統合 全体
ファイル※:src/models/unet3d.py
※記事最初に記載してある参考リポジトリのもの
from types import SimpleNamespace
import torch
import torch.nn as nn
import torch.nn.functional as F
import timm
from src.augs import aug3d, Mixup, CutmixSimple
from .layers import ResnetEncoder3d, UnetDecoder3d, SegmentationHead3d
from ._base import BaseModel
class Net(BaseModel):
def __init__(
self,
cfg: SimpleNamespace,
inference_mode: bool = False,
):
super().__init__(cfg=cfg, inference_mode=inference_mode)
self.cfg = cfg
self.inference_mode = inference_mode
# Last channels (~1.25x speedup on Ampere GPUs)
if not inference_mode and \
torch.cuda.is_available() and \
torch.cuda.get_device_properties(0).major >= 8:
self.last_channels= True
else:
self.last_channels= False
# Augs
self.mixup = Mixup(cfg.mixup_beta)
self.cutmix = CutmixSimple()
# Encoder
self.backbone = ResnetEncoder3d(
cfg= cfg,
inference_mode= inference_mode,
**vars(cfg.encoder_cfg),
)
ecs= self.backbone.channels[::-1]
if self.last_channels:
self.backbone = self.backbone.to(memory_format=torch.channels_last_3d)
# Decoder + Heads
self.decoder= UnetDecoder3d(
encoder_channels= ecs,
**vars(cfg.decoder_cfg),
)
self.seg_head= SegmentationHead3d(
in_channels= self.decoder.decoder_channels[-1],
out_channels= cfg.seg_classes,
)
if cfg.deep_supervision:
self.aux_head= SegmentationHead3d(
in_channels= ecs[0],
out_channels= cfg.seg_classes,
)
def proc_flip(self, x_in, dim):
# Flip TTA
i = torch.flip(x_in, dim)
f = self.backbone.forward_features(i)
f = f[::-1]
f = f[:len(self.cfg.decoder_cfg.decoder_channels)+1]
p = self.seg_head(self.decoder(f)[-1])
return torch.flip(p, dim)
def forward(self, batch):
# Augs
if self.training:
x= batch["input"].float() # bs,c,t,h,w
x = x / 255.0
y= batch["target"].float()
# Cutmix
if torch.rand(1)[0] < self.cfg.cutmix_p:
x, y = self.cutmix(x, y)
x, y= aug3d.coarse_dropout_3d(x, y, p=0.5)
x, y= aug3d.rotate(x, y, p= 1.0, dims=[(-2,-1)])
x, y= aug3d.flip_3d(x, y)
x, y= aug3d.swap_dims(x, y, dims=(-2,-1))
# Mixup
if torch.rand(1)[0] < self.cfg.mixup_p:
x, y = self.mixup(x, y)
else:
x= batch.float()
x = x / 255.0
if self.last_channels:
x = x.to(memory_format=torch.channels_last_3d)
# Forward pass
x_in = x
x_feats = self.backbone.forward_features(x)
x = x_feats[::-1]
x = x[:len(self.cfg.decoder_cfg.decoder_channels)+1] # remove unused feature maps
x= self.decoder(x)
x_seg= self.seg_head(x[-1])
if self.training:
# Loss
loss= self.loss_fn(x_seg, y)
# Aux loss (max pixel vs max label)
x_aux= F.max_pool3d(x_seg, kernel_size=4, stride=4)
y_aux= F.max_pool3d(y, kernel_size=4, stride=4)
loss_aux= self.loss_fn(x_aux, y_aux)
loss += 0.25 * loss_aux
if self.cfg.deep_supervision:
# Downsample ys (way faster than upsample)
x_aux= self.aux_head(x[-2])
y_aux= F.avg_pool3d(y, kernel_size=2)
loss_aux= self.loss_fn(x_aux, y_aux)
loss += 0.1 * loss_aux
return {
"logits": x_seg,
"loss": loss,
}
else:
# TTA during inference
if self.cfg.tta:
p1 = self.proc_flip(x_in, [2])
p2 = self.proc_flip(x_in, [3])
x_seg = torch.mean(torch.stack([x_seg, p1, p2]), dim=0)
else:
pass
return x_seg
if __name__ == "__main__":
from src.configs.r3d200 import cfg
from src.models.layers import count_parameters
m= Net(cfg=cfg)#.cuda()
m= m.eval()
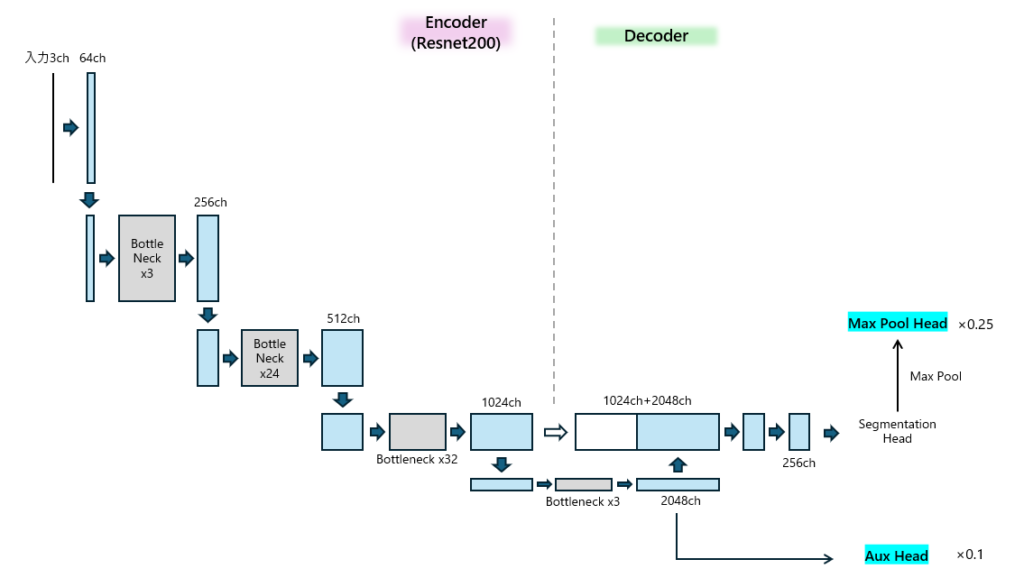
print("n_param: {:_}".format(count_parameters(m)))前回のDecoderの解説で載せた図とほとんど変わりません。
異なる点はMax Pool HeadとAux Head(中間出力を抜き出してSegmentationしているもの)です。
これらのHeadが何者かについては解法解説の”Loss計算”をご覧ください。
【参考】解法解説:Cryo-ET 鞭毛モーターの3D検出 | Kaggle BYU 2025 1位解法解説
解法解説でもありましたが、今回はおおよその位置を当てることができれば良いので、解像度が粗い状態でも予測させて学習させるためのものとなります。
これらの層は学習の時のみ有効であり、推論時は無視されます。
コードを分割して見ていきます。
class Net コンストラクタ
これまで作成したEncoder(ResnetEncoder3d), Decoder(UnetDecoder3d), Segmentation(SegmentationHead3d)を使って各モデルを生成しつつ、最後にAux Headを生成してます。
class Net(BaseModel):
def __init__(
self,
cfg: SimpleNamespace,
inference_mode: bool = False,
):
super().__init__(cfg=cfg, inference_mode=inference_mode)
self.cfg = cfg
self.inference_mode = inference_mode
# Last channels (~1.25x speedup on Ampere GPUs)
if not inference_mode and \
torch.cuda.is_available() and \
torch.cuda.get_device_properties(0).major >= 8:
self.last_channels= True
else:
self.last_channels= False
# Augs
self.mixup = Mixup(cfg.mixup_beta)
self.cutmix = CutmixSimple()
# Encoder
self.backbone = ResnetEncoder3d(
cfg= cfg,
inference_mode= inference_mode,
**vars(cfg.encoder_cfg),
)
ecs= self.backbone.channels[::-1]
if self.last_channels:
self.backbone = self.backbone.to(memory_format=torch.channels_last_3d)
# Decoder + Heads
self.decoder= UnetDecoder3d(
encoder_channels= ecs,
**vars(cfg.decoder_cfg),
)
self.seg_head= SegmentationHead3d(
in_channels= self.decoder.decoder_channels[-1],
out_channels= cfg.seg_classes,
)
if cfg.deep_supervision:
self.aux_head= SegmentationHead3d(
in_channels= ecs[0],
out_channels= cfg.seg_classes,
)Aux Headについて、解法解説のみでは中間出力をどのHeadに入れてlogitsを計算してるかわかりませんでしたが、コードを見るとSementationHead3dを使用しているのがわかりますね。
前回のDecoderのところで、Encoderの各layerの出力チャネルリストが反転したものが渡されているとありますが、その反転がEncoder生成の後にecs = self.backbone.channels[::-1]というところでされています。
cfgについてもわからないとコードの内容がよくわからなくなると思うためcfgについても記載しておきます。
cfgには外部で定義されている設定が入ってます。cfgの内容は補足に張り付けておくのでご覧ください。チャネル設定に関するところだけ抽出して記載しておきます。
- seg_classes: 1
- decoder_channels: (256, )
【補足】cfg内容
from ._base import cfg
from types import SimpleNamespace
# Dataloader
cfg.batch_size= 12
cfg.num_workers= 6
# Dataset
cfg.dataset_type= "_3d"
cfg.data_dir= "./data/processed/"
# Model
cfg.model_type = "unet3d"
cfg.backbone = "r3d200"
cfg.roi_size= (64, 672, 672)
cfg.in_chans= 1
cfg.seg_classes= 1
cfg.deep_supervision= True
# Encoder
encoder_cfg= SimpleNamespace()
encoder_cfg.drop_path_rate= 0.2
encoder_cfg.use_checkpoint= True
cfg.encoder_cfg= encoder_cfg
# Decoder
decoder_cfg= SimpleNamespace()
decoder_cfg.decoder_channels= (256,)
decoder_cfg.upsample_mode= "deconv" # nontrainable | deconv | deconvgroup | pixelshuffle
cfg.decoder_cfg= decoder_cfg
# Loss
cfg.loss_type= "src.losses.SmoothBCE"
loss_cfg= SimpleNamespace()
loss_cfg.pos_weight= 256.0
loss_cfg.smooth= 1e-3
cfg.loss_cfg= loss_cfg
# Label cfg
cfg.kernel_sigma= 1.0
cfg.kernel_size= 7
cfg.kernel_type= "smooth"
# Other
cfg.logging_steps= 25
cfg.eval_epochs= 50
cfg.save_epochs= 50
cfg.epochs= 401def proc_flip
こちらはTTA(Test Time Augmentation)で行う入力のFlip処理となります。
私が未熟なだけかもしれませんが、ぱっと見で少々混乱したので処理の詳細を説明しておきます。
- torch.flipで入力(x_in)を指定した次元(dim: D or H or W)に対して反転
- self.backboneがEncoder(ResnetEncoder3d)であり、その中で定義しているforward_featuresメソッドを使用して各layerの出力リスト(list[torch.Tensor])を取得
- f[::-1]で出力リストを反転, すなわちEncoderの最終出力が先頭
- cfg.decoder_cfg.decoder_channelsは(256, )であり1要素のタプルであるためlen(cfg.decoder…)は1。そのため、f[:len(…)+1]はf[:2]となるため、Encoderの最終出力とその一つ前の出力を取得
- self.decoder(f)の返り値はDecoder各段の出力リスト(list[torch.Tensol])。self.decoder(f)[-1]ではDecoderの最終出力を取得
- self.seg_headにDecoderの最終出力を入れて3D logits(p)を取得
- 最後に反転させた次元を戻してreturn
class Net(nn.Module)
...
def proc_flip(self, x_in, dim):
# Flip TTA
i = torch.flip(x_in, dim)
f = self.backbone.forward_features(i)
f = f[::-1]
f = f[:len(self.cfg.decoder_cfg.decoder_channels)+1]
p = self.seg_head(self.decoder(f)[-1])
return torch.flip(p, dim)def forward
いつものforward定義ですが、解法にあったMax Pool HeadのlossとAux Headのloss取得するところがあるので、そこについて話そうと思います。
class Net(nn.Module)
...
def forward(self, batch):
# Augs
if self.training:
x= batch["input"].float() # bs,c,t,h,w
x = x / 255.0
y= batch["target"].float()
# Cutmix
if torch.rand(1)[0] < self.cfg.cutmix_p:
x, y = self.cutmix(x, y)
x, y= aug3d.coarse_dropout_3d(x, y, p=0.5)
x, y= aug3d.rotate(x, y, p= 1.0, dims=[(-2,-1)])
x, y= aug3d.flip_3d(x, y)
x, y= aug3d.swap_dims(x, y, dims=(-2,-1))
# Mixup
if torch.rand(1)[0] < self.cfg.mixup_p:
x, y = self.mixup(x, y)
else:
x= batch.float()
x = x / 255.0
if self.last_channels:
x = x.to(memory_format=torch.channels_last_3d)
# Forward pass
x_in = x
x_feats = self.backbone.forward_features(x)
x = x_feats[::-1]
x = x[:len(self.cfg.decoder_cfg.decoder_channels)+1] # remove unused feature maps
x= self.decoder(x)
x_seg= self.seg_head(x[-1])
if self.training:
# Loss
loss= self.loss_fn(x_seg, y)
# Aux loss (max pixel vs max label)
x_aux= F.max_pool3d(x_seg, kernel_size=4, stride=4)
y_aux= F.max_pool3d(y, kernel_size=4, stride=4)
loss_aux= self.loss_fn(x_aux, y_aux)
loss += 0.25 * loss_aux
if self.cfg.deep_supervision:
# Downsample ys (way faster than upsample)
x_aux= self.aux_head(x[-2])
y_aux= F.avg_pool3d(y, kernel_size=2)
loss_aux= self.loss_fn(x_aux, y_aux)
loss += 0.1 * loss_aux
return {
"logits": x_seg,
"loss": loss,
}
else:
# TTA during inference
if self.cfg.tta:
p1 = self.proc_flip(x_in, [2])
p2 = self.proc_flip(x_in, [3])
x_seg = torch.mean(torch.stack([x_seg, p1, p2]), dim=0)
else:
pass
return x_seglossの前に一応3D Unetのメイン処理部分についてだけ記載しておきます。やってることは、先ほどのproc_flipでflip処理抜いただけのものになります。
# Forward pass
x_in = x
x_feats = self.backbone.forward_features(x)
x = x_feats[::-1]
x = x[:len(self.cfg.decoder_cfg.decoder_channels)+1] # remove unused feature maps
x= self.decoder(x)
x_seg= self.seg_head(x[-1])それではlossのところに入っていきます。
if self. trainingの中に諸々のloss計算が入ってるので学習時のみloss計算するようになってますね。
loss = self.loss_fn(x_seg, y)は見たまんまでメインのSegmentation Headのlossです。
※loss_fnは外部で定義しているloss関数。
次の”Aux loss (max pixel vs max label)”のところがMax Pool Headのlossになってます。
Segmentation Headの結果(x_seg)をmax_pool3dして、GT(y)もmax_pool3d。それらでloss計算した後、解法にあった通りに0.25倍してlossに加算。
そして、if self.cfg.deep_supervisionの中がAux Headのlossです。
ここでのxはdecoderの出力結果(list[torch.Tensor])であり、詳細な中身としては[Decoder最終出力、1つ前の出力(一番深いところ)]になります。
そのためself.aux_head(x[-2])のx[-2]は一番深いところの出力となります。冒頭に示した図の2048chと書いてあるところです。
GTもx_auxとD, H, Wのサイズを合わせるため、avg_pool3dをして、その後loss計算、0.1倍して加算で終わりとなります。
if self.training:
# Loss
loss= self.loss_fn(x_seg, y)
# Aux loss (max pixel vs max label)
x_aux= F.max_pool3d(x_seg, kernel_size=4, stride=4)
y_aux= F.max_pool3d(y, kernel_size=4, stride=4)
loss_aux= self.loss_fn(x_aux, y_aux)
loss += 0.25 * loss_aux
if self.cfg.deep_supervision:
# Downsample ys (way faster than upsample)
x_aux= self.aux_head(x[-2])
y_aux= F.avg_pool3d(y, kernel_size=2)
loss_aux= self.loss_fn(x_aux, y_aux)
loss += 0.1 * loss_auxせっかくなので最後にTTAをどう行っているかだけも見ておきます。
flip無し予測結果x_seg、2次元部分(D)を入れ替えての予測結果p1、3次元部分(H)を入れ替えての予測結果p2をstackして、0次元で平均をしてます。
ここでW方向のflipが無いのは、解法で推論時間10時間ぎりぎりだったとあるので、時間が足りないので外した程度の理由だと思われます。
“stackして0次元で平均する”について補足しておくと、x_seg, p1, p2の3つをstackすると[3, B, C, D, H, W]となるので、0次元で平均して[B, C, D, H, W]にしているというイメージになります。
class Net(nn.Module)
...
if self.training:
...
else: # 推論時
# TTA during inference
if self.cfg.tta:
p1 = self.proc_flip(x_in, [2])
p2 = self.proc_flip(x_in, [3])
x_seg = torch.mean(torch.stack([x_seg, p1, p2]), dim=0)
else:
pass
return x_segまとめ
以上でloss計算含めた3D Unetのモデル定義は完了となります。
コード全体の抽象化が進んでいるので、使いまわされてリファクタリングされてきたような感じがあり、歯ごたえある内容でした。
解法ではモデルをさらっと話してるだけですが、実装するとなるとエンジニア力が問われる内容でしたね。
残りは学習と推論となり、次回は学習部分について解説していこうと思います。
