
これまでKaggle BYU 2025 1位解法のモデル部分を解説してきました。
今回から学習・推論について書いていこうと思いましたが、Datasetクラスのところに一番重要なものがあったため、まずはDatasetについて解説しようと思います。
コンペ:BYU – Locating Bacterial Flagellar Motors 2025 | Kaggle
参考リポジトリ:GitHub – brendanartley/BYU-competition: 1st place solution for the BYU Locating Bacterial Flagellar Motors Competition
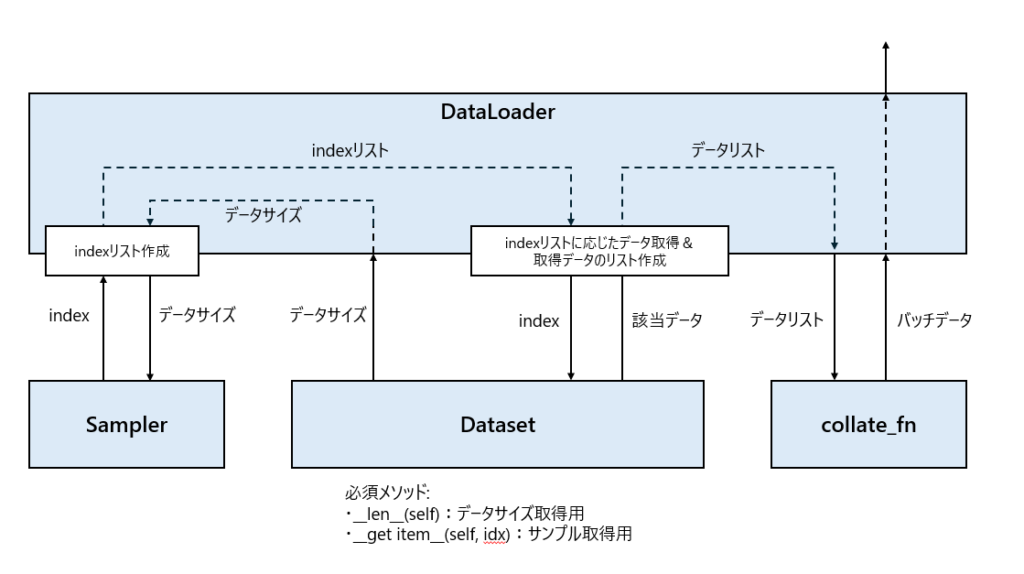
【参考】DataLoader/Datasetの役割
DataLoaderとDatasetの役割を度々忘れるので備忘録も兼ねてまとめました。
DataLoaderとDatasetの役割と言いつつ、Samplerとcollate_fnもまとめてます。
- DataLoader: Dataset, Sampler, collate_fnを組み合わせてバッチデータを作成
- Dataset: データセットを保持して、バッチデータを構成する1サンプルのデータを作成
- Sampler: Datasetからどのサンプルを取得するかを示すindexを取得
- collate_fn: 取得したデータサンプル集をバッチにするための微調整※&バッチデータ作成
※微調整の例)サンプルサイズがそれぞれ異なった場合にPadding等で調整するなど
CustomDatasetクラス
ファイル※:src/data/_3d.py
※記事最初に記載してある参考リポジトリのもの
import os
import pickle
import glob
from copy import deepcopy
from tqdm import tqdm
import pandas as pd
import numpy as np
import scipy
from PIL import Image
import torch
class CustomDataset(torch.utils.data.Dataset):
def __init__(self, cfg, df, mode="train"):
self.cfg = cfg
self.mode = mode
if mode == "train":
self.aug = cfg.train_aug
else:
self.aug = cfg.val_aug
# Keep only positive samples
if mode == "train":
df = df[df["coordinates"].apply(lambda x: len(eval(x))) != 0]
df= df.reset_index(drop=True)
self.df= df
# Load imgs + labels
imgs= []
labels= []
if self.mode == "test":
self.imgs= [0]*len(df)
self.labels= [0]*len(df)
else:
# Create kernel
ks= cfg.kernel_size
kernel = self._compute_kernel(
kernel_size= ks,
kernel_type= cfg.kernel_type,
kernel_sigma= cfg.kernel_sigma,
)
for row in tqdm(df.itertuples(), total=len(df), disable=self.cfg.local_rank!=0):
row= row._asdict()
row["coordinates"]= eval(row["coordinates"])
# Load img
fpath= "{}/fold_{}/{}.npy".format(
cfg.data_dir,
row["fold"],
row["tomo_id"]
)
img= np.load(fpath, mmap_mode='r')
imgs.append(img)
# Create label (stored in 8x smaller size than input)
label= np.zeros([_//8 for i, _ in enumerate(img.shape)], dtype=np.float32)
t,h,w= label.shape
# Iterate motors
for z,y,x in row["coordinates"]:
# Relative -> Absolute
z= int(z*t)
y= int(y*h)
x= int(x*w)
# Bounding box around label
z_min, z_max= max(z - ks//2, 0), min(z + ks//2 + 1, t)
y_min, y_max= max(y - ks//2, 0), min(y + ks//2 + 1, h)
x_min, x_max= max(x - ks//2, 0), min(x + ks//2 + 1, w)
# Trim kernel if edge overlaps
kz_min= max(0, -1*(z - (ks//2)))
ky_min= max(0, -1*(y - (ks//2)))
kx_min= max(0, -1*(x - (ks//2)))
kz_max= t - z + ks//2
ky_max= h - y + ks//2
kx_max= w - x + ks//2
# Max to avoid overlap w/ other points
label[z_min:z_max, y_min:y_max, x_min:x_max] = np.maximum(
label[z_min:z_max, y_min:y_max, x_min:x_max],
kernel[kz_min:kz_max, ky_min:ky_max, kx_min:kx_max],
)
labels.append(label)
self.imgs= imgs
self.labels= labels
self.df= df
def _compute_kernel(self, kernel_size, kernel_type, kernel_sigma):
assert kernel_size%2!=0
center_offset = kernel_size//2
# Precompute the kernel
zz, yy, xx = np.meshgrid(
np.arange(kernel_size) - center_offset,
np.arange(kernel_size) - center_offset,
np.arange(kernel_size) - center_offset,
indexing="ij",
)
if kernel_type == "smooth":
kernel = np.exp(-(zz**2 + yy**2 + xx**2) / (2 * kernel_sigma**2)).astype(np.float16)
elif kernel_type == "hard":
kernel = (zz**2 + yy**2 + xx**2 <= ((kernel_size//2)**2)).astype(np.uint8)
else:
raise ValueError(f"kernel_type: {kernel_type} not recognized.")
return kernel
def _load_one(self, row):
# Fpaths
in_path= os.path.join(self.cfg.data_dir, row["tomo_id"])
fpaths= sorted(glob.glob(in_path + "/*"))
z_shape= len(fpaths)
# Stack
arr = [np.array(Image.open(_).convert("L")) for _ in fpaths]
y_shape, x_shape= arr[0].shape
arr = np.stack(arr)
# Resize
t,h,w= self.cfg.img_size
zoom_factor= (t / arr.shape[0], h / arr.shape[1], w / arr.shape[2])
arr= scipy.ndimage.zoom(arr, zoom_factor, order=1)
arr= np.clip(arr, 0, 255).astype(np.uint8)
return {
"img": arr,
"z_shape": z_shape,
"y_shape": y_shape,
"x_shape": x_shape,
}
def __len__(self,):
return len(self.imgs)
def __getitem__(self, idx):
img= self.imgs[idx]
label= self.labels[idx]
scales= None
if self.mode == "train":
# Increase label size (1/8 -> 1/1)
label= scipy.ndimage.zoom(label.copy(), (8,8,8), order=0)
# Params
z,y,x= self.cfg.roi_size
# Random crop
lz,ly,lx= label.shape
z_start= np.random.randint(0, max(lz - z, 1))
y_start= np.random.randint(0, max(ly - y, 1))
x_start= np.random.randint(0, max(lx - x, 1))
z_end= z_start + z
y_end= y_start + y
x_end= x_start + x
img= img[z_start:z_end, y_start:y_end, x_start:x_end]
label= label[z_start:z_end, y_start:y_end, x_start:x_end]
# Random rescale
if np.random.random() < self.cfg.rescale_p:
scales = np.random.uniform(low=0.5, high=1.3, size=3)
img= scipy.ndimage.zoom(img, scales, order=0)
label= scipy.ndimage.zoom(label, scales, order=0)
# Crop (to get back to roi_size)
lz,ly,lx= label.shape
z_start= np.random.randint(0, max(lz - z, 1))
y_start= np.random.randint(0, max(ly - y, 1))
x_start= np.random.randint(0, max(lx - x, 1))
z_end= z_start + z
y_end= y_start + y
x_end= x_start + x
img= img[z_start:z_end, y_start:y_end, x_start:x_end]
label= label[z_start:z_end, y_start:y_end, x_start:x_end]
# Pad (to get back to roi_size)
lz,ly,lx= label.shape
pad_z = max(z - lz, 0)
pad_y = max(y - ly, 0)
pad_x = max(x - lx, 0)
pad_zl= np.random.randint(0, pad_z + 1)
pad_zr= pad_z - pad_zl
pad_yl= np.random.randint(0, pad_y + 1)
pad_yr= pad_y - pad_yl
pad_xl= np.random.randint(0, pad_x + 1)
pad_xr= pad_x - pad_xl
pad_width= [(pad_zl, pad_zr), (pad_yl, pad_yr), (pad_xl, pad_xr)]
label= np.pad(label, pad_width, constant_values=0)
img= np.pad(img, pad_width, constant_values=np.random.randint(0, 255))
# Color inversion
if np.random.random() < 0.25:
img= 255 - img
# Reduce label size (1/1 -> 1/8)
label= scipy.ndimage.zoom(label, (0.125, 0.125, 0.125), order=0)
label= label.astype(np.float16)
elif self.mode == "test":
row= self.df.iloc[idx].to_dict()
data= self._load_one(row=row)
img= data["img"]
label= np.zeros(0)
else:
img= img.copy()
label= label.copy()
# Add channel
img= img[np.newaxis, ...]
label= label[np.newaxis, ...]
if self.mode == "test":
return {
"tomo_id": row["tomo_id"],
"input": img,
"target": label,
"z_shape": data["z_shape"],
"y_shape": data["y_shape"],
"x_shape": data["x_shape"],
}
else:
return {
"input": img,
"target": label,
}
if __name__ == "__main__":
from src.configs.r3d200 import cfg
cfg.local_rank= 0
cfg.rescale_p = 1.0
df_train= pd.read_csv("./data/processed/folds_all.csv")
df_train= df_train[df_train["fold"] != -1]
df_train= df_train[df_train["fold"] != cfg.fold].head(1)
ds= CustomDataset(cfg, df=df_train, mode="train")
for i in range(len(df_train)):
for k,v in ds[i].items():
print(i, k, v.shape)
pass- コンストラクタで入力データと正解ラベルを用意
- def __len__(self)でデータセットのサイズを返す
- def __getitem__(self, idx)で1サンプルを作成して返す
というDatasetの基本的な流れとなってます。
解法で正解ラベルをGaussian heatmapにして、かつheatmapの解像度を1/8にしたことが評価指標に対して効果的だったとありました。
その部分が、CustomDatasetクラスのコンストラクタで行われていたので、そちらについて重点的に見ていこうと思います。
Gaussian heatmap カーネル作成
コンストラクタの前にGaussian heatmapのカーネル作成するメソッドから先に話していきます。
カーネルを作成しているメソッドはdef _compute_kernel(…)になります。
def _compute_kernel(self, kernel_size, kernel_type, kernel_sigma):
assert kernel_size%2!=0
center_offset = kernel_size//2
# Precompute the kernel
zz, yy, xx = np.meshgrid(
np.arange(kernel_size) - center_offset,
np.arange(kernel_size) - center_offset,
np.arange(kernel_size) - center_offset,
indexing="ij",
)
if kernel_type == "smooth":
kernel = np.exp(-(zz**2 + yy**2 + xx**2) / (2 * kernel_sigma**2)).astype(np.float16)
elif kernel_type == "hard":
kernel = (zz**2 + yy**2 + xx**2 <= ((kernel_size//2)**2)).astype(np.uint8)
else:
raise ValueError(f"kernel_type: {kernel_type} not recognized.")
return kernel図2にGaussian heatmapカーネルのイメージを示します。本来は3Dですが見やすさ重視で2Dにしてます。
カーネル中心が最大値であり、中心からの距離に応じてガウス分布しているものを作成してます。今回は2Dでイメージ書いてますが、ガウス分布がx, y, zの各方向に広がってると思って見てください。
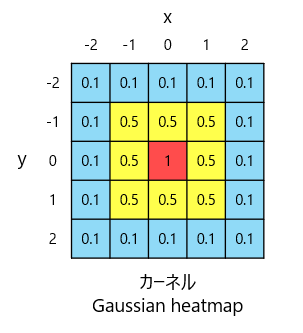
※記載している数値はサンプル
以下に、参考までに式を示しておきます。こちらは本来の3Dのもので記載してます。
x=0, y=0, z=0、すなわち中心であれば1。中心からのユークリッド距離に応じて値が下がっていくものになってます。
コンストラクタ
コンストラクタにおいて先ほど紹介したカーネルを使用してGaussian heatmapを適用した3Dラベルを作成してます。
実際にイメージ図を見ながら解説してきますが、先ほどと同様に見やすさ重視で本来は3Dのところを2Dで記載しているので、同じ内容が3D方向に広がってると思って見てください。
class CustomDataset(torch.utils.data.Dataset):
def __init__(self, cfg, df, mode="train"):
self.cfg = cfg
self.mode = mode
if mode == "train":
self.aug = cfg.train_aug
else:
self.aug = cfg.val_aug
# Keep only positive samples
if mode == "train":
df = df[df["coordinates"].apply(lambda x: len(eval(x))) != 0]
df= df.reset_index(drop=True)
self.df= df
# Load imgs + labels
imgs= []
labels= []
if self.mode == "test":
self.imgs= [0]*len(df)
self.labels= [0]*len(df)
else:
# Create kernel
ks= cfg.kernel_size
kernel = self._compute_kernel(
kernel_size= ks,
kernel_type= cfg.kernel_type,
kernel_sigma= cfg.kernel_sigma,
)
for row in tqdm(df.itertuples(), total=len(df), disable=self.cfg.local_rank!=0):
row= row._asdict()
row["coordinates"]= eval(row["coordinates"])
# Load img
fpath= "{}/fold_{}/{}.npy".format(
cfg.data_dir,
row["fold"],
row["tomo_id"]
)
img= np.load(fpath, mmap_mode='r')
imgs.append(img)
# Create label (stored in 8x smaller size than input)
label= np.zeros([_//8 for i, _ in enumerate(img.shape)], dtype=np.float32)
t,h,w= label.shape
# Iterate motors
for z,y,x in row["coordinates"]:
# Relative -> Absolute
z= int(z*t)
y= int(y*h)
x= int(x*w)
# Bounding box around label
z_min, z_max= max(z - ks//2, 0), min(z + ks//2 + 1, t)
y_min, y_max= max(y - ks//2, 0), min(y + ks//2 + 1, h)
x_min, x_max= max(x - ks//2, 0), min(x + ks//2 + 1, w)
# Trim kernel if edge overlaps
kz_min= max(0, -1*(z - (ks//2)))
ky_min= max(0, -1*(y - (ks//2)))
kx_min= max(0, -1*(x - (ks//2)))
kz_max= t - z + ks//2
ky_max= h - y + ks//2
kx_max= w - x + ks//2
# Max to avoid overlap w/ other points
label[z_min:z_max, y_min:y_max, x_min:x_max] = np.maximum(
label[z_min:z_max, y_min:y_max, x_min:x_max],
kernel[kz_min:kz_max, ky_min:ky_max, kx_min:kx_max],
)
labels.append(label)
self.imgs= imgs
self.labels= labels
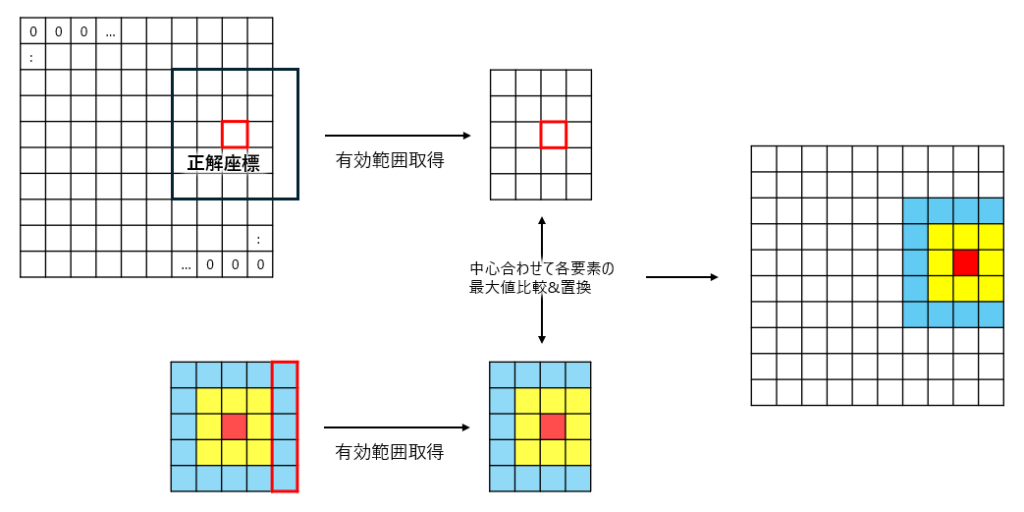
self.df= df図3はGaussian heatmap(以後カーネル)をラベルに適用するイメージとなります。
流れとしては、
- 作成したいラベルサイズの0埋めnumpy.array作成
- カーネル中心とラベル内の正解座標の位置を合わせる
- それぞれ対応する要素を比較して、大きい方の値に置換
図に示せてはないですが、作成したいラベルサイズは入力データの1/8です。
ここで解像度をあえて粗くすることにより、評価指標によく適合できたとのことです。
※評価指標については解法解説を参照
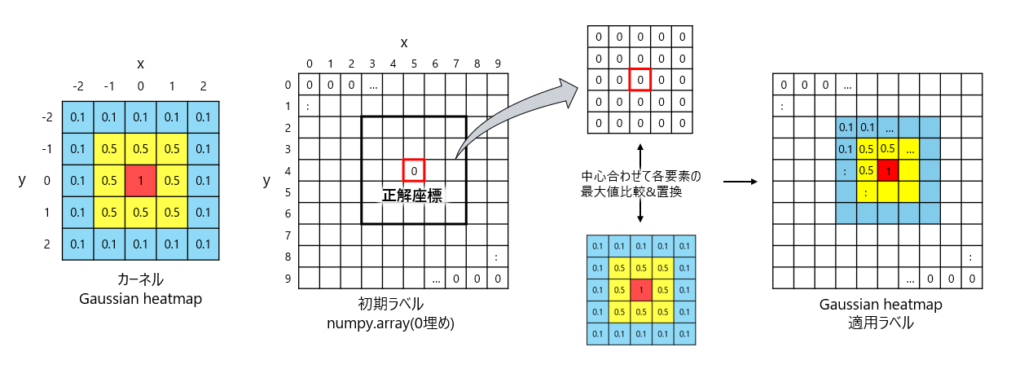
0埋めしてるのに比較して置換する意味あるのかと思うかもしれませんが、複数の正解座標が存在する場合があるので、おそらくそのための対応となります。
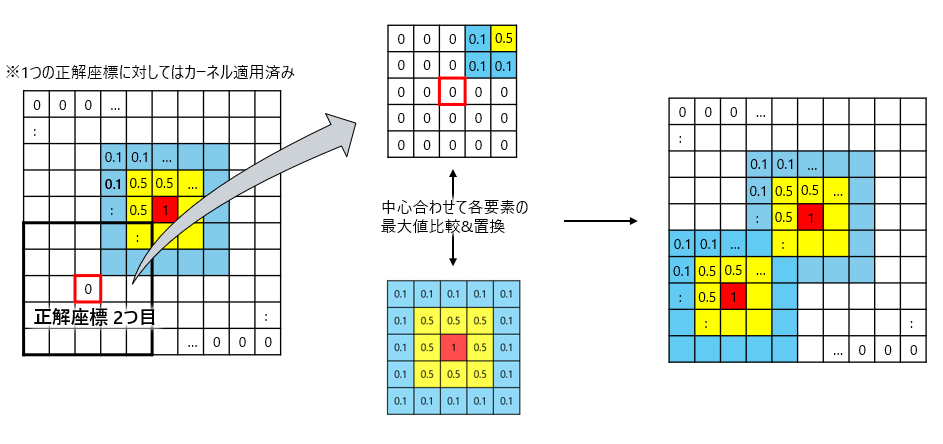
図4に複数の正解座標がある場合を示してます。
やってることは先ほどと同じですが、既に1つのカーネルが適用されている点が異なります。
こうなると最大値を比較して置換する意味が出てきます。
最後に正解座標の位置がラベルの端に存在しており、適用するカーネルがはみ出してしまう場合を図5に示してます。
コード上は少々ややこしく見えますが、やっていることははみ出す部分を除いてるだけです。
コンストラクタにおいて重要なところは以上となります。
__len__, __getitem__について
__len__についてはデータセットのサイズを返すだけなので割愛します。
__getitem__もCropなどのAugmentationの一部をやってますが、やっていることは以下の基本的な内容となるのでこちらも割愛させていただきます。
- 保持しているデータから指定されたindexの値を取得
- Crop等の基本的なAugmentationを入力データ、ラベルにそれぞれ適用
- Augmentationしたものをまとめて、1つのデータサンプルとしてreturn
まとめ
以上が解法におけるDatasetの内容となります。
Dataloaderはこれを呼んでるだけなのでDatasetの中身さえわかってしまえば問題ないです。
ダウンサンプリングする(解像度を粗くする)、Gaussian heatmapを適用する ことで正解の許容範囲を広くして学習の安定化を図りつつ、評価指標にミートさせるという地味だけど非常に重要なことをしていました。
モデル含めて、やってること一つ一つは基本的なんですが、そういう基本的なことの積み重ね方と使いどころの適切さ具合がすごいなと感心してばかりです。
次回はようやく学習のところに入ります。山場は超えた気がするので残りはささっといきたいところ。
最後までご覧いただきありがとうございました。
