
異常検知や分類問題においてほぼ起こりうるのがデータの不均衡問題です。
検知したい異常や、特定の分類クラスがどうしても少なってしまうということは多々あります。
不均衡クラスに対処する方法としては、多数クラスを減らすダウンサンプリングや、少数クラスを増やすオーバーサンプリングがあります。
今回は、多いものも少ないものも確率的に調整してくれるWeightedRandomSamplerを紹介&試していきます。
WeightedRandomSamplerとは
各クラスのデータ量に応じて重み付けを行い、少数クラスには大きい値、多数クラスには小さい値をつけます。
学習時にランダムにデータを取ってきますが、その際に重みが大きいものの出現頻度を大きくします。
同じデータを重複して呼び出すことが可能です。
そのため、クラスデータが少ないものでも学習中に何度も呼び出されるため、そのクラスのデータを擬似的に増やすことができます。
注意点
先ほど同じデータを重複して呼び出すとありましたが、当然そのままだとそのクラスについては過学習を引き起こします。
そのためWeightedRandomSamplerを使用する場合は強めのAugmentataionをかけることがほぼ必須です。
強めと言ってるのは同じデータでも同じには見えなくさせるような処理のこととなります。
画像であれば回転、反転、Mask、Mixup等、音声であればピッチ調整、Mask、Mixupなどです。
もし上記のようなAugmentationをかけられないようなタスクの場合※、WeightedRandomSamplerの使用は控えた方が良いということになります。
※例えば走行シーンの分析など位置関係が重要であり、そのままの画像が必要なタスク等
使用データ
この記事を執筆してる2026年にkaggleで開催されていた動物の音声分類コンペ”BirdCLEF+ 2026″のデータを使用しました。
本記事の内容を試すだけなら”train.csv”のみをダウンロードすれば大丈夫です。
こちらのコンペのデータは234クラスの分類をするんですが、少ないクラスは1サンプルしか存在しないのに対して、多いクラスは500サンプル程度あるという、いわゆる”ロングテール”な分布をしてるデータとなっています。
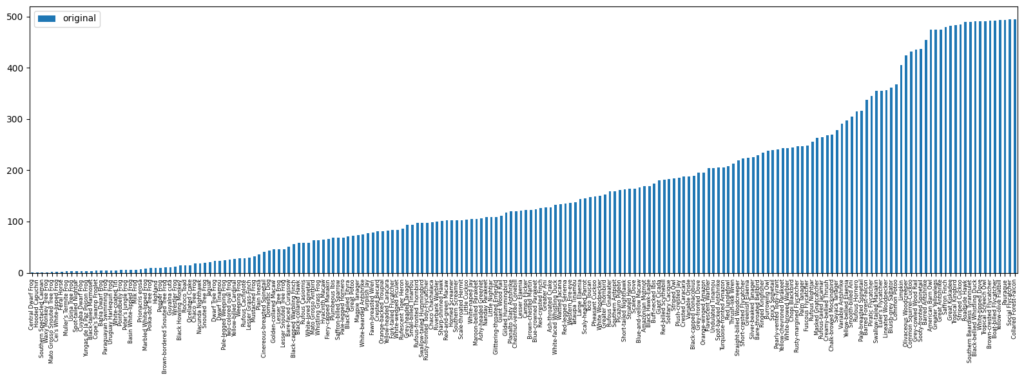
分類クラスが多いうえに、サンプル数の差も非常に大きいため、このまま学習させたとしても数サンプルから数十サンプル程度しかない少数クラスは学習がうまくされないためWeightedRandomSamplerでバランスを整えてみます。
サンプルコード
- 必要ライブラリのimport
import pandas as pd
from torch.utils.data import DataLoader, WeightedRandomSampler, Dataset
import matplotlib.pyplot as plt2. Dataset定義
class WRSDataset(Dataset):
def __init__(self, df: pd.DataFrame):
self.df = df
def __len__(self):
return len(self.df)
def __getitem__(self, idx):
row = self.df.iloc[idx]
return row["common_name"]3. 各サンプルの重み設定の関数
WeightedRandomSamplerにおいては各サンプルごとの重みが必要であるため、全サンプル数分の重みを取得する処理です。
重みは、そのクラスの総数の逆数を使います。
def get_sample_weight(df: pd.DataFrame):
class_counts = df["common_name"].value_counts()
sample_weights = (
df["common_name"]
.map(lambda x: 1.0 / class_counts[x])
.to_numpy()
)
return sample_weights4. データ読み込み~DataLoader定義
全サンプルの重みを元にWeightedRandomSamplerを作り、DataLoaderに定義したDatasetとSamplerを渡してます。
data_path = "path/to/train.csv"
df = pd.read_csv(data_path)
sample_weights = get_sample_weight(df).copy()
dataset = WRSDataset(df)
sampler = WeightedRandomSampler(
weights=sample_weights,
num_samples=len(sample_weights),
replacement=True
)
dataloader = DataLoader(
dataset,
batch_size=512,
sampler=sampler,
num_workers=12
)5. WeightedRandomSample前後のクラスカウント & 描画
# WeightedRandomSample前のクラスカウント
original_counts = df["common_name"].value_counts()
# WeightedRandomSample後のクラスカウント
sampled_labels = []
for batch in dataloader:
sampled_labels.extend(batch)
sampled_counts = pd.Series(sampled_labels).value_counts()
compare_df = pd.DataFrame({
"original": original_counts,
"sampled": sampled_counts,
}).fillna(0)
plot_df = compare_df.sort_values(
"original",
ascending=True
).head(200)
plot_df.plot.bar(
y=["original", "sampled"],
figsize=(16, 6)
)
plt.xticks(
rotation=90,
fontsize=6
)
plt.tight_layout()
plt.show()実行結果
前述のコードを実行した結果が以下のものとなります。
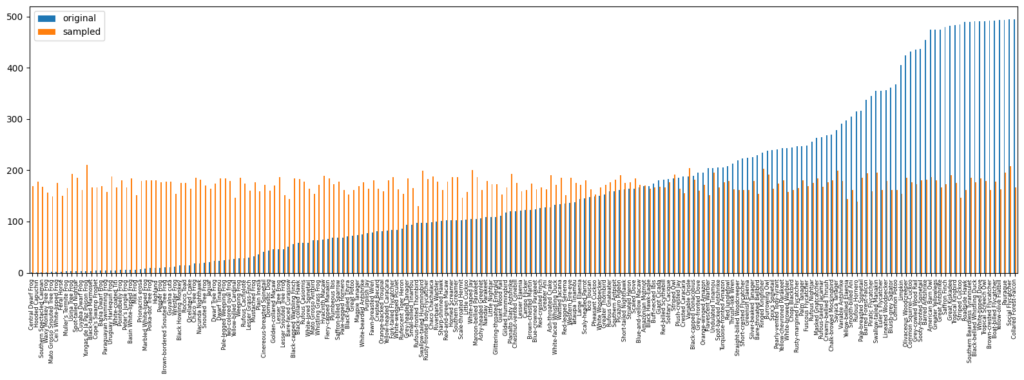
青がWeightedRandomSampler適用前、オレンジが適用後となっています。
確率的に調整されるため完全に均一にはなっておりませんが、少ないサンプルのものは増やされ、多いサンプルのものは減らされていることが確認できます。
参考までにですが、このデータを持ってきたkaggleコンペにおいてスコアの算出方法ですが、各クラスについてROC-AUCを求めて、最後に全てのクラスのROC-SUCを平均するというものでした。
WeightedRandomSamplerを適用する前は最大で0.75程度であり、これは少数クラスについてはほとんど間違えてるスコアになります。
一方でWeightedRandomSamplerを適用した後のスコアは0.85程度まで跳ね上がり、少数クラスについても学習が進んだとみられます。※
※AugmentationとしてMixupとMaskを入れており、同じデータだとしても毎回異なるデータに見えるようにしています。
おわりに
不均衡データのバランスを整えるWeightedRandomSamplerについて紹介および検証してみました。
モデルや後処理をどれだけ頑張っても入力がよろしくなければ精度は出ないため、もし精度出ないとなった場合は基本を振り返りデータの分布を確認して、不均衡であればWeightedRandomSamplerを試してみると良いかもしれません。
(私は度々前処理が甘くて反省するんですが、毎回懲りずに前処理をサラッとやってしまって時間を無駄にしてしまってるので戒めも兼ねて…)
最後までご覧いただきありがとうございました。
