
以前の記事でFlowMatcingについて説明しており、その中でMNISTを用いたFlowMatchingのデモ動画を紹介してました。
前回記事:Flow Matching – マルチモーダル生成のコア技術 | Hibamo | AI &Analytics Techlog
今回は上記の説明内で紹介してるデモの実装内容について紹介します。
前回記事はまだご覧になっていない方は是非前回記事もご覧ください。
実装内容
githubで公開してるためそちらをご覧ください。
hibamo0488/flow_matching_mnist
実行環境
| 項目 | 内容 |
|---|---|
| OS | WSL2 / Ubuntu24.04 |
| CPU | Intel Core Ultra 7 |
| メモリ | 128GB |
| GPU | RTX 5070 Ti |
| VRAM | 16GB |
| 仮想環境 | Docker |
| エディタ | VS Code |
※メモリとVRAMはそれぞれ8GB程度でもおそらく動作可能です。
セットアップ
前述のgithubリポジトリのREADMEに記載してあるため、そちらをご確認ください。
ディレクトリ構成
flow_matching_mnist
├── checkpoints
│ └── README.md
├── data
│ └── README.md
├── movie
│ └── README.md
├── samples
│ ├── sample_model
│ │ └── resnet11_epoch100.pth
│ └── sample_movie
│ ├── README.md
│ ├── flow_animation_digit0.gif
│ ├── flow_animation_digit1.gif
│ └── flow_animation_digit9.gif
├── src
│ ├── fm_animation.ipynb
│ ├── infer.ipynb
│ ├── model
│ │ ├── __init__.py
│ │ └── resnet11.py
│ └── train.ipynb
├── README.md
├── dockerfile
├── compose.yaml
├── pyproject.toml
└── uv.lock
ディレクトリ・ファイル説明
| ディレクトリ | 説明 |
|---|---|
| checkpoints | 学習途中・学習済みのモデル保存先 |
| data | MNISTデータのダウンロード先 |
| movie | デノイズ過程を示す動画の保存先 |
| samples | 既に作成済みのモデルと上記動画の置き場 |
| src | 学習、推論、デノイズ過程の動画作成 |
src/ ファイル説明
| ファイル | 説明 |
|---|---|
| model/resnet11.py | 学習・推論するモデル(Resnet11層)の定義 |
| train.ipynb | MNISTのダウンロード+モデルの学習 |
| infer.ipynb | 学習済みモデルを用いたベクトル場推論 ノイズ画像からMNIST画像に変換される過程を静止画で可視化 |
| fm_animation.ipynb | 複数のノイズデータを作成して、指定したMNIST画像の分布に向かう様子を動画化 PCAで2次元に圧縮してノイズ画像(28×28=784次元)を点(2次元)で表現 |
学習処理解説
モデルが学習するのは条件に応じたベクトル場になります。
条件毎にベクトルを予測し、正解ベクトルとのMSEを最小化するように学習します。
今回のMNIST題材における条件はノイズベクトル(=ノイズ画像)、現時点のデノイズステップ数、入力プロンプト。
※フィジカルAIや動画生成では上記条件に加えて、”ロボットの状態(各軸の角度、位置)”や”前フレームの画像”なども条件として加わる。
先ほどの3つの条件をモデルに入力するにあたって以下のような処理を行っています。
入力プロンプト、タイムステップをembeddingしてる理由については後述。
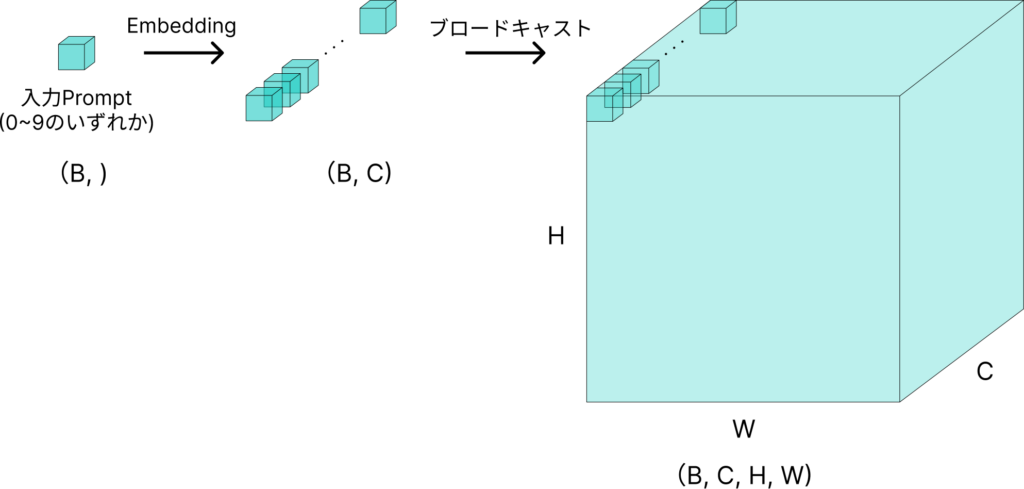
1. 入力プロンプトのembedding
ブロードキャストで(B, C)が(B, C, H, W)になっていますが、ここでの(H, W)はMNISTの画像サイズ(H: 28, W:28)です。
図ではブロードキャストを明記してますが、実際は以下の3のところでノイズ画像とチャネル方向にスタックする際にPytorchで自動的にブロードキャストしてます。
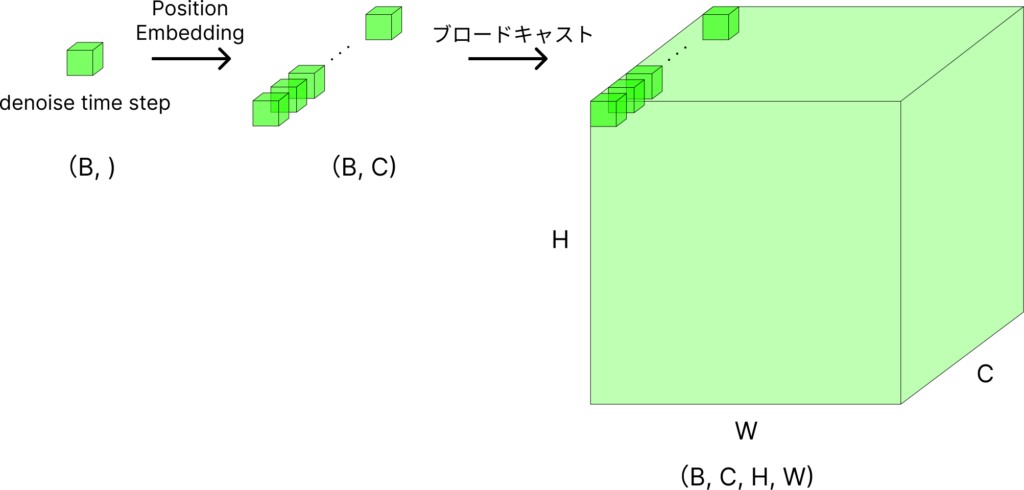
2. デノイズステップ数のposition embedding
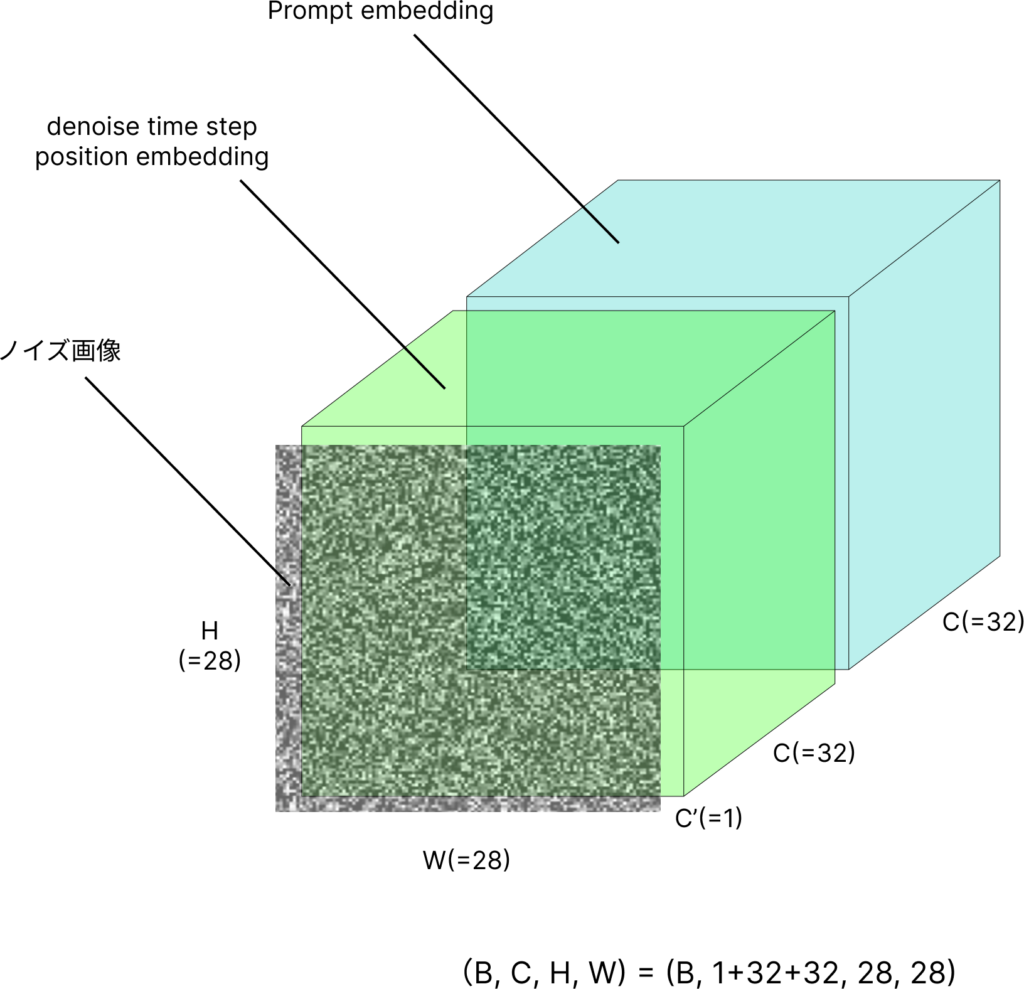
3. ノイズ画像 , 入力プロンプトembedding, デノイズステップembeddingのチャネル方向スタック
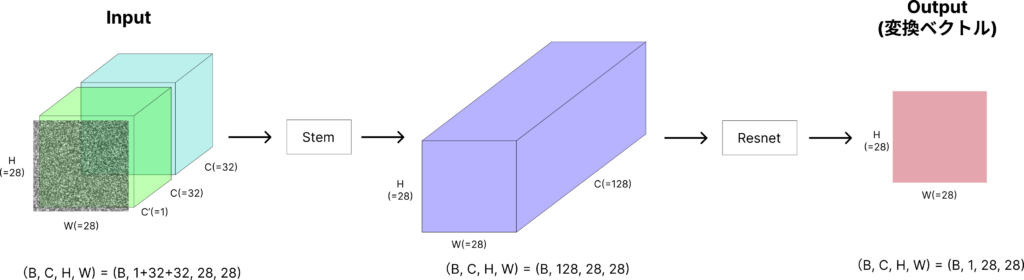
上記のように処理した入力データをStem→Resnetと渡して、最後に出力されるベクトルでMSE lossを取得という流れになります。
学習したモデルを用いてデノイズするときは以下のようになります。

推論で求めた変換ベクトルにタイムステップdtを掛け合わせて、ノイズデータにelement-wiseで加算していくという流れでデノイズしていきます。
※タイムステップは0から1の中で分割して定めます。10stepで完全ノイズ→クリーンデータにする場合は1ステップ(dt)が0.1ということになります。
【補足】入力プロンプトとデノイズステップのembeddingについて
embeddingした理由について、理論としてこうしたら良いというのがあるかと思いますが、今回は実験的にそのようにしたらうまくいったという理由でembeddingしてます。
以下にembedding導入へと至った流れを記載します。
- 最初に試したときはノイズ画像(1ch)、入力プロンプト(1ch)、デノイズステップ(1ch)の合計3chで検証 ※入力プロンプトとデノイズステップは同じ値をH×Wにブロードキャスト
- 結果としては、学習がうまく進まず、デノイズしても数字が浮かび上がらず、意味のない白い線が出てくるのみ
- ”表現力不足”が学習が進まない原因であると推測
- ノイズベクトルやデノイズステップ数など無数に存在するため、単純なMNIST題材だとしても学習する内容はおそらく非常に複雑になっている
- 表現力を上げるための最初の対応としてはモデルの変更を実施
- シンプルなCNNからResnet11に変更した結果、lossの減少を確認
- それでもまだloss値は若干高く、デノイズさせてみても数字が出てこないという状況
- 入力データの表現力も上げるためにembeddingを実施
- 結果としてlossが十分に下がり、数字が浮かび上がってくるようになり、効果的であることを確認
以上がembeddingを導入した経緯となります。
最後に
画像生成、動画生成、フィジカルAIで活用されるFlowMatchingについてMNISTを題材にして実装してみました。
論文ではベクトル場を学習させるための理論と損失関数の設計が語られており、数式が多く難解に見えますが、実装としてはMSE lossを取得すればよいだけというシンプルなものでした。(入力の工夫は必要ですが)
参考までにですが、モデルをGoogleのVLMのPaliGemmaにして、入力にロボットの状態とカメラ画像を追加すると2025年に話題になったフィジカルAIのπ0になります。
FlowMatchingの肝が条件に基づいたベクトル場を学習・推論ということだと思うため、こちらを理解しておけば先ほど紹介したフィジカルAI含め、各種生成モデルの理解や構築が捗ると思います。
最後までご覧いただきありがとうございました。

