
2025年にPhisical IntelligenceがリリースしたフィジカルAIモデルの”π0”においてアクション生成として使われているFlow Matching。
Flow Matchingは画像や動画生成にも使用される技術となっています。
今後の人手不足のことを考えるとフィジカルAIの期待値は言わずもがな。
また、画像や動画生成については資料用のデータ作成やエンタメ応用が主流ですが、個人的には深層学習用の学習・評価データに応用するのが熱いのではないかと思っています。
専用モデルを自前で構築できるように、コア技術のFlow Matchingについてまとめました。
以降はFlow MatchingをFMと略します。
元論文:2210.02747
Flow Matching要点
- 学習および推論するのはノイズデータをクリーンデータへ変換するベクトル場
- ベクトル場を学習するための損失関数が設計されており、それを適用することでベクトル場が学習される
- 拡散モデル(DDPM)ではノイズからクリーンデータまでのデノイズステップが数百程度必要なのに対して、FMでは10ステップ程度のみのため処理が高速
背景・従来手法
Flow Matchingと並んで登場するのがDDPM(Denoising Diffusion Probabilistic Models)。いわゆる拡散モデルです。
ざっくり言うと、ノイズデータから除去するノイズを予測して、デノイズしていくモデルです。
DDPMについて語ると長くなるため詳細割愛しますが、デノイズ過程でランダム性が存在します。
以下の図に示すようにランダム性があるためデノイズからクリーンデータに至るまでの変換過程が直線的ではないです。
また、小ステップでのデノイズを想定してるため、デノイズステップが数百程度必要となっています。
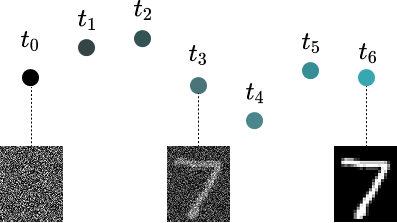
図では6ステップだが本来は数百ステップ程度
上記の理由により速度が求められるフィジカルAIなどでは処理が遅いというボトルネックがありました。
Flow Matching概要
冒頭でも述べたようにノイズデータからクリーンデータを復元するためのベクトル場を予測させるという概念になります。
モデルではなく概念であるため、モデル自体はDNN、CNN、決定木のどれでも使えます。
確率ではなく正解に向かって決まった方向と速度で復元されていくため、デノイズステップ1回のデノイズ量を大きくしても問題なく、10step程度で十分であり推論回数が少ないため高速です。
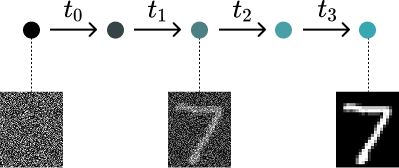
図では4ステップだが本来は10ステップ程度
ベクトル場学習のための損失関数

論文において色々書いてましたがおそらくここが本質というところを抜粋しました。(他にも重要なところあったらすみません…)
こちらがベクトル場を学習させるための損失関数となります。
ぱっと見た感じだと圧倒されそうになりますが、やってることとしては以下です。
”入力データ(本記事ではノイズデータが該当)を変換するためのベクトルについて、予測したベクトルと正解ベクトルの平均二乗誤差を取得。”
すなわちベクトル場のMSEを取ってるということです。
ノイズ状態が無数に存在するため、各状態における変換ベクトルを大量に予測させて、MSEを取得し、MSEを最小化していけばベクトル場が学習されていくというものです。
ベクトル場の学習イメージについては以下で図を用いてもう少しだけ説明してみます。
ベクトル場学習のイメージ
以下のようにノイズデータとクリーンデータ(以下ではMNISTの画像)を用意すれば正解ベクトルを作れるので、あとはひたすらノイズデータを入れてベクトルを予測させてMSEを取得して、最適化したらベクトル場を予測するモデルができあがります。
ちなみに様々なベクトルを最適化(平均化)していくと統合されたベクトル場ができあがり、論文で”Merginal Vector Field”と書かれているものはおそらくこのことになります。
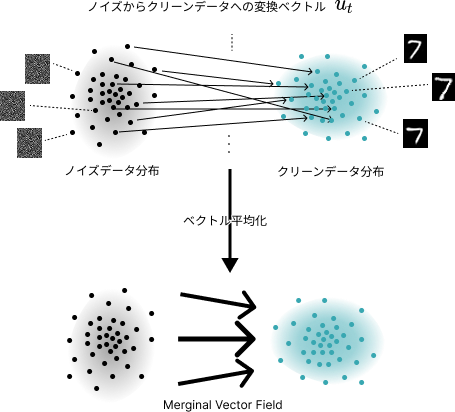
図. ベクトル場の学習イメージ
また、FlowMatchingの論文ではノイズのみを条件としてますが、入力テキストや、アクションの場合はロボットの状態なども条件となり、各条件毎にベクトル場を学習させることができます。
これによって画像生成や動画生成、フィジカルAIにおいては入力テキストやロボット状態によって出力や動作を変えるということを実現しています。
以下で入力テキストによって出力が変わる様子を示したデモを紹介します。
MNISTによるFlow Matchingデモ
※別記事において以下のデモコードを紹介しようと思うので本記事では割愛。その際に処理内容についても紹介予定。
’26/6/2 追記:
処理内容に関する記事公開しました。
FlowMatchingでMNIST画像生成にトライ | Hibamo | AI &Analytics Techlog
データを揃えやすく学習させやすいということでMNISTを題材にしてみました。
まずは以下がデモ動画です。
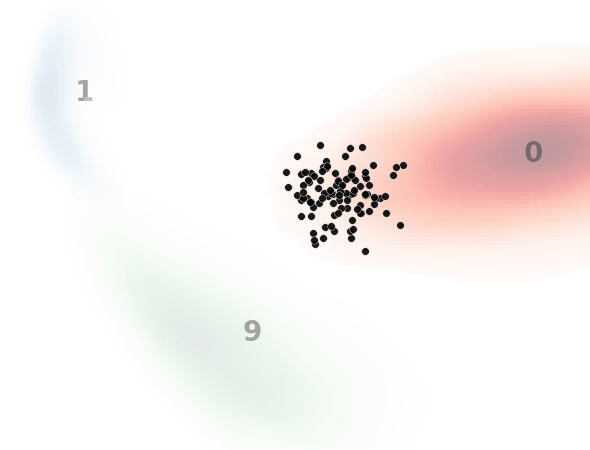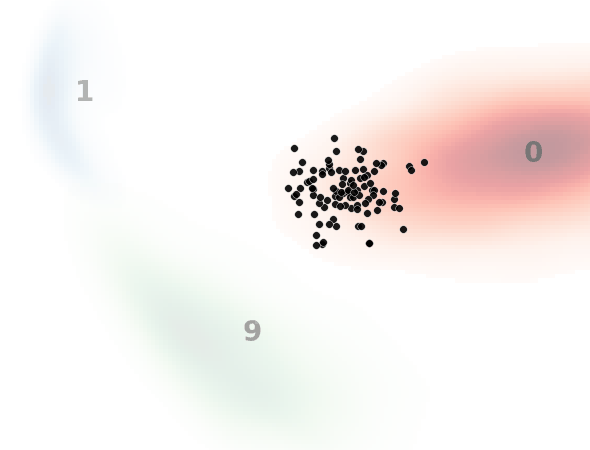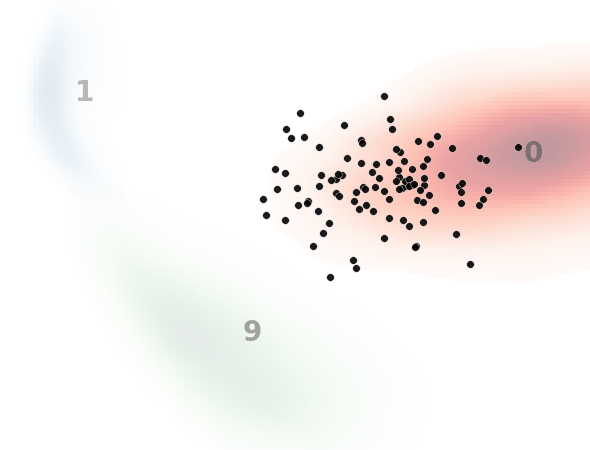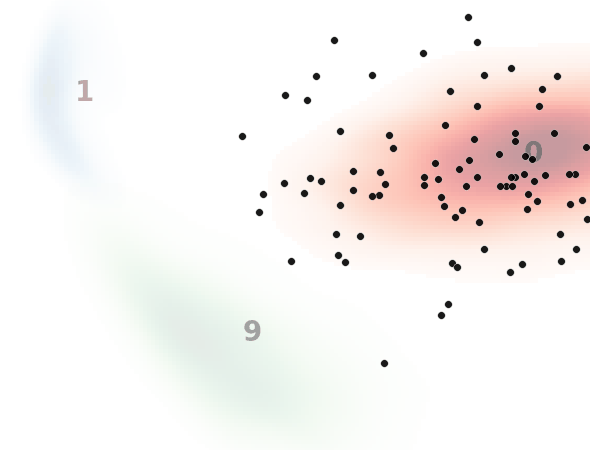

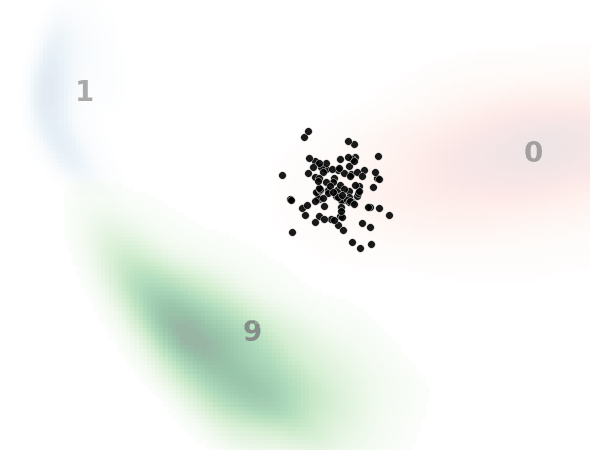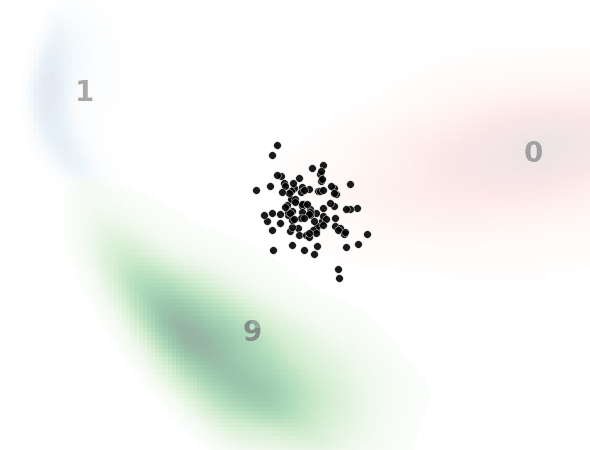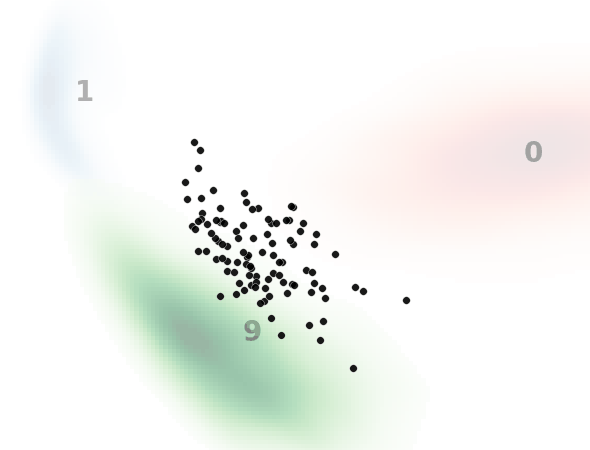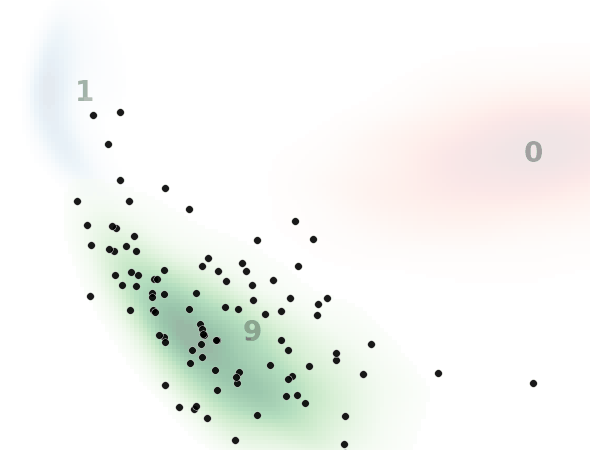
見方ですが、黒い点一つ一つがノイズ画像を示してます。本来はH×W×1(白黒)の次元ですが、主成分分析によって2次元に落とし込んでます。
背景の数字とヒートマップはMNISTのデータ分布を示してます。
0と書いてある赤いところはMNISTで0の画像の分布、1と書いてある青いところは1の画像の分布、9と書いてある緑のところは9の画像の分布です。
ベクトル場を予測するモデルは共通のモデルを使用してます。(それぞれでモデルを用意してるわけではない)
入力テキスト、すなわち指示分として”0″, “1”, “9”のいずれかを入力して、入力した数字のMNIST画像を生成するようにノイズデータを復元しており、それがノイズデータ(黒点)の移動として表現されてます。
ノイズ状態に応じてベクトル場が更新されていくため完全な直線とはなりませんが、直線的に動いているのと、ノイズ画像が指定した画像に向かっている(ノイズ除去されている)ことがわかります。
一方で最終的に指定した画像分布から外れるノイズデータがいます。
これは前述したように平均的なベクトル場を学習してるため、ノイズの初期状態によっては外れた方向に誘導するベクトル場に乗ってしまうものがいるためと考えられます。(モデルや学習の改善余地残っているというのもありますが。)
最後に
画像、動画、アクション生成といった自然言語以外の生成のコア技術となるFlow Matchingについてまとめました。
画像、動画、アクション以外にも、例えばLiDAR点群やその他センサーデータなど、様々なデータの生成にも応用できる気がします。
冒頭でも述べたように、基盤モデル含めた深層学習用のデータ収集のための生成AIを活用しようとしたとき、独自モデル構築などもありうると思うため、本記事の内容が参考になれば幸いです。
最後までご覧いただきありがとうございました。

