
今回はKaggle “Jigsaw – Agile Community Rules Classification“を通じて大規模言語モデルのタスク適用方法について見ていこうと思います。
(本読んでたら投稿が空いてしまいました。)
コンペ内容
概要
アメリカ版5chことRedditに関するコンペになります。(5chより平和で実用的とのこと)
5chのスレッドにあたる”Subreddit”というものがあり、それぞれのSubredditにルールが存在。
投稿されたコメントがルールに違反しているかどうかを判定するコンペ。
データ
学習データには以下が含まれてます。
- body: コメント
- rule: そのコメントの違反判定の元となったと考えられるルール
- subreddit: そのコメントが書かれたsubreddit
- positive_example_{1,2}: そのルールに違反しているコメントのサンプル
- negative_example_{1,2}: そのルールに違反していないコメントのサンプル
- rule_violation: そのコメントが違反(1)か否(0)かの2値
評価指標
“column-averaged AUC”で評価
図1に基本的なAUCのイメージを示してます。
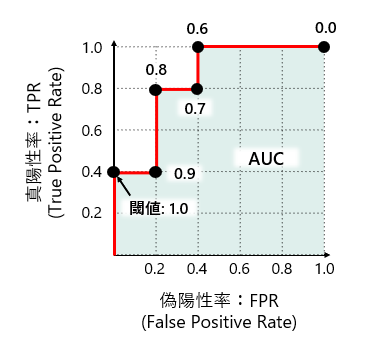
基本的なAUCでは横軸を偽陽性率(FPR)、縦軸を真陽性率(TPR)として、予測値に対して閾値を1から0にしていった時のFPR、TPRをプロットしていきROC曲線を作成し、AUC(Area Under Curve)を算出します。
基本的なAUCを踏まえて、以下の図2にcolumn-averaged AUCのイメージを示してます。
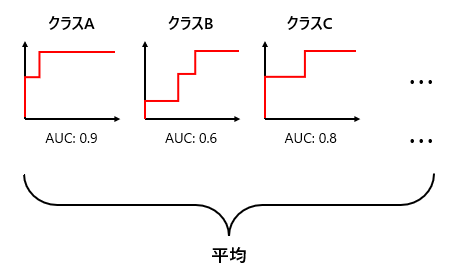
今回はクラスがおそらく各ルールなのでしょうかね。
各クラス毎にAUCを取得して、最後に全てを平均するといった感じです。
1位解法 コア要素
- 7B以上のモデルを載せるために”Unsloth”※を使用
※軽量かつ容易にファインチューニング実装するもの - ファインチューニング時にYesかNo以外の余分なTokenも出してくるが、処理で不要Token削除(性能改善への効果大)
- 推論時にYes, Noの表現ばらつきがあるため、ばらついてもYes, Noと判定できるように表現マップを作製
例){Yes, yes, Y, YES, True} → Yes
※モデルの改造みたいなことはなく、素直でシンプルなファインチューニングをしてるだけであり、学習の安定化と後処理がメインという感じでした。
まとめ
仕事でもここ2年くらい大規模言語モデルを取り扱っており、冒頭で本を読んでたと書きましたが、読んでた本は”Kaggleではじめる大規模言語モデル入門”という本であり、実務と本それぞれから大規模言語モデルについて知見を仕入れてました。
モデルの改造をすることはありますが、LoRAで学習重みを追加したり、入力や出力ヘッドを変えるということがたまにある程度であり、内部構造を変えるみたいなことはほぼ見当たりません。
実際はこのコンペのようにモデルはあまりいじらず後処理をうまくやるか、もしくは入力データをいい感じにするかということが多い印象です。
そのため、途中見ていただいたように解法としてはあまり述べることが無く、実際に実装を見ても特段語ることがないという感じだったりもします。
これまではこの後に実装見ていきましたが、今回はどうしようかと考えてます…
(見ても仕方がないという感じもあり…)
大規模言語モデルはモデル自体をどういじるかというより、モデルサイズが大きいため、推論の高速化やリソースに載せるための軽量化といったところの方が重要である気がするため、コンペ関係なく、高速化や軽量化技術についてそれぞれ単発で簡単に実装しながら紹介していこうかなと予定してます。
コンペと解法自体についてはシンプルな内容となりましたがこれで以上となります。

